Have you ever had an analysis in which there was a large set of contrasts, all of interest, and you were worried about multiple testing? An eventual effect would be missed by a simple Bonferroni correction, but you did not know what else to do? Or did you have a set of different studies and you wished to obtain a style of meta-analytic result, indicating whether there would be evidence across all of them, without requiring the studies to be all consistently significant?
The Non-Parametric Combination (NPC) solves these issues. It is a way of performing joint inference on multiple data collected on the same experimental units (e.g., same subjects), all with minimal assumptions. The method was proposed originally by Pesarin (1990, 1992) [see references below], independently by Blair and Karninski (1993), and described extensively by Pesarin and Salmaso (2010). In this blog entry, the NPC is presented in brief, with emphasis on the modifications we introduce to render it feasible for brain imaging. The complete details are in our paper that has just been published in the journal Human Brain Mapping.
NPC in a nutshell
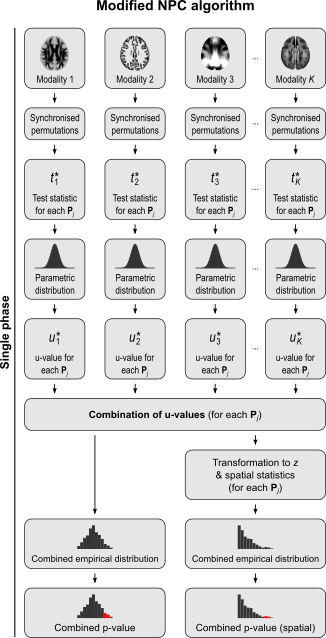
The NPC consists of, in a first phase, testing each hypothesis separately using permutations that are performed synchronously across datasets; these tests are termed partial tests. The resulting statistics for each and every permutation are recorded, allowing an estimate of the complete empirical null distribution to be constructed for each one. In a second phase, the empirical p-values for each statistic are combined, for each permutation, into a joint statistic. As such a combined joint statistic is produced from the previous permutations, an estimate of its empirical distribution function is immediately known, and so is the p-value of the joint test. A flowchart of the original algorithm is shown below; click to see it side-by-side with the modified one (described below).
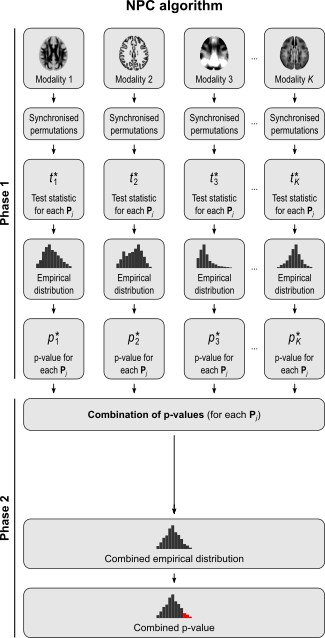
A host of combining functions
The null hypothesis of the NPC is that null hypotheses for all partial tests are true, and the alternative hypothesis that any is false, which is the same null of a union-intersection test (UIT; Roy, 1953). The rejection region depends on how the combined statistic is produced. Various combining functions, which produce such combined statistics, can be considered, and some of the most well known are listed in the table below:
| Method |
Statistic |
p-value |
| Tippett |
 |
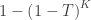 |
| Fisher |
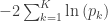 |
 |
| Stouffer |
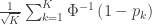 |
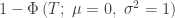 |
| Mudholkar–George |
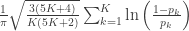 |
 |
In the table,  is the number of partial tests, and the remaining of the variables follow the usual notation (see the Table 1 in the paper for the complete description). Many of these combining functions were proposed over the years for applications such as meta-analyses, and many of them assume independence between the tests being combined, and will give incorrect p-values if such assumption is not met. In the NPC, lack of dependence is not a problem, even if these same functions are used: the synchronised permutations ensure that any dependence, if existing, is taken into account, and this is done so implicitly, with no need for explicit modelling.
is the number of partial tests, and the remaining of the variables follow the usual notation (see the Table 1 in the paper for the complete description). Many of these combining functions were proposed over the years for applications such as meta-analyses, and many of them assume independence between the tests being combined, and will give incorrect p-values if such assumption is not met. In the NPC, lack of dependence is not a problem, even if these same functions are used: the synchronised permutations ensure that any dependence, if existing, is taken into account, and this is done so implicitly, with no need for explicit modelling.
The different combining functions lead to different rejection regions for the null hypothesis. For the four combining functions in the table above, the respective rejection regions are in the figure below.
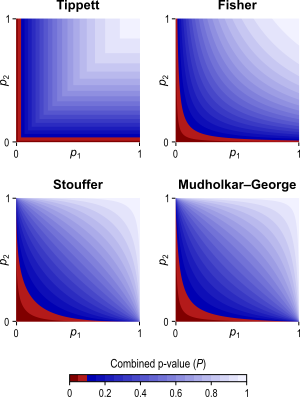
The combining functions can be modified to allow combination of tests so as to favour hypotheses with concordant directions, or be modified for bi-directional tests. Click on the figure above for examples of these cases (again, see the paper for the complete details).
Two problems, one solution
The multiple testing problem is well known in brain imaging: as an image comprises thousands of voxels/vertices/faces, correction is necessary. Bonferroni is in general too conservative, and various other approaches have been proposed, such as the random field theory. Permutation tests provide control over the familywise error rate (FWER) for the multiple tests across space, requiring only the assumption of exchangeability. This is all well known; see Nichols and Hayasaka (2003) and Winkler et al. (2014) for details.
However, another type of multiple testing is also common: analyses that test multiple hypotheses using the same model, multiple pairwise group comparisons, multiple and distinct models, studies using multiple modalities, that mix imaging and non-imaging data, that consider multiple processing pipelines, and even multiple multivariate analyses. All these common cases also need multiple testing correction. We call this multiple testing problem MTP-II, to discern it from the well known multiple testing problem across space, described above, which we term MTP-I.
One of the many combining functions possible with NPC, the one proposed by Tippett (1931), has a further property that makes it remarkably interesting. The Tippett function uses the smallest p-value across partial tests as its test statistic. Alternatively, if all statistics are comparable, it can be formulated in terms of the maximum statistic. It turns out that the distribution of the maximum statistic across a set of tests is also the distribution that can be used in a closed testing procedure (Marcus et al., 1976) to correct for the familywise error rate (FWER) using resampling methods, such as permutation. In the context of joint inference, FWER-correction can also be seen as an UIT. Thus, NPC offers a link between combination of multiple tests, and correction for multiple tests, in both cases regardless of any dependence between such tests.
This means that the MTP-II, for which correction in the parametric realm is either non-existing or fiendishly difficult, can be accommodated easily. It requires no explicit modelling of the dependence between the tests, and the resulting error rates are controlled exactly at the test level, adding rigour to what otherwise could lead to an excess of false positives without correction, or be overly conservative if a naïve correction such as Bonferroni were attempted.
Modifying for imaging applications
As originally proposed, in practice NPC cannot be used in brain imaging. As the statistics for all partial tests for all permutations need to be recorded, an enormous amount of space for data storage is necessary. Even if storage space were not a problem, the discreteness of the p-values for the partial tests is problematic when correcting for multiple testing, because with thousands of tests in an image, ties are likely to occur, further causing ties among the combined statistics. If too many tests across an image share the same most extreme statistic, correction for the MTP-I, while still valid, becomes less powerful (Westfall and Young, 1993; Pantazis et al., 2005). The most obvious workaround — run an ever larger number of permutations to break the ties — may not be possible for small sample sizes, or when possible, requires correspondingly larger data storage.
The solution is loosely based on the direct combination of the test statistics, by converting the test statistics of the partial tests to values that behave as p-values, using the asymptotic distribution of the statistics for the partial tests. We call these as “u-values”, in order to emphasise that they are not meant to be read or interpreted as p-values, but rather as transitional values that allow combinations that otherwise would not be possible.
For spatial statistics, the asymptotic distribution of the combined statistic is used, this time to produce a z-score, which can be subjected to the computation of cluster extent, cluster mass, and/or threshold-free cluster enhancement (TFCE; Smith and Nichols, 2009). A flow chart of the modified algorithm is shown below. Click to see it side-by-side with the original.
More power, fewer assumptions
One of the most remarkable features of NPC is that the synchronised permutations implicitly account for the dependence structure among the partial tests. This means that even combining methods originally derived under the assumption of independence can be used when such independence is untenable. As the p-values are assessed via permutations, distributional restrictions are likewise not necessary, liberating NPC from most assumptions that thwart parametric methods in general. This renders NPC a good alternative to classical multivariate tests, such as MANOVA, MANCOVA, and Hotelling’s T2 tests: each of the response variables can be seen as an univariate partial test in the context of the combination, but without the assumptions that are embodied in these old multivariate tests.
As if all the above were not already sufficient, NPC is also more powerful than such classical multivariate tests. This refers to its finite sample consistency property, that is, even with fixed sample size, as the number of modalities being combined increases, the power of the test also increases. The power of classical multivariate tests, however, increases up to a certain point, then begins to decrease, eventually reaching zero when the number of combining variables match the sample size.
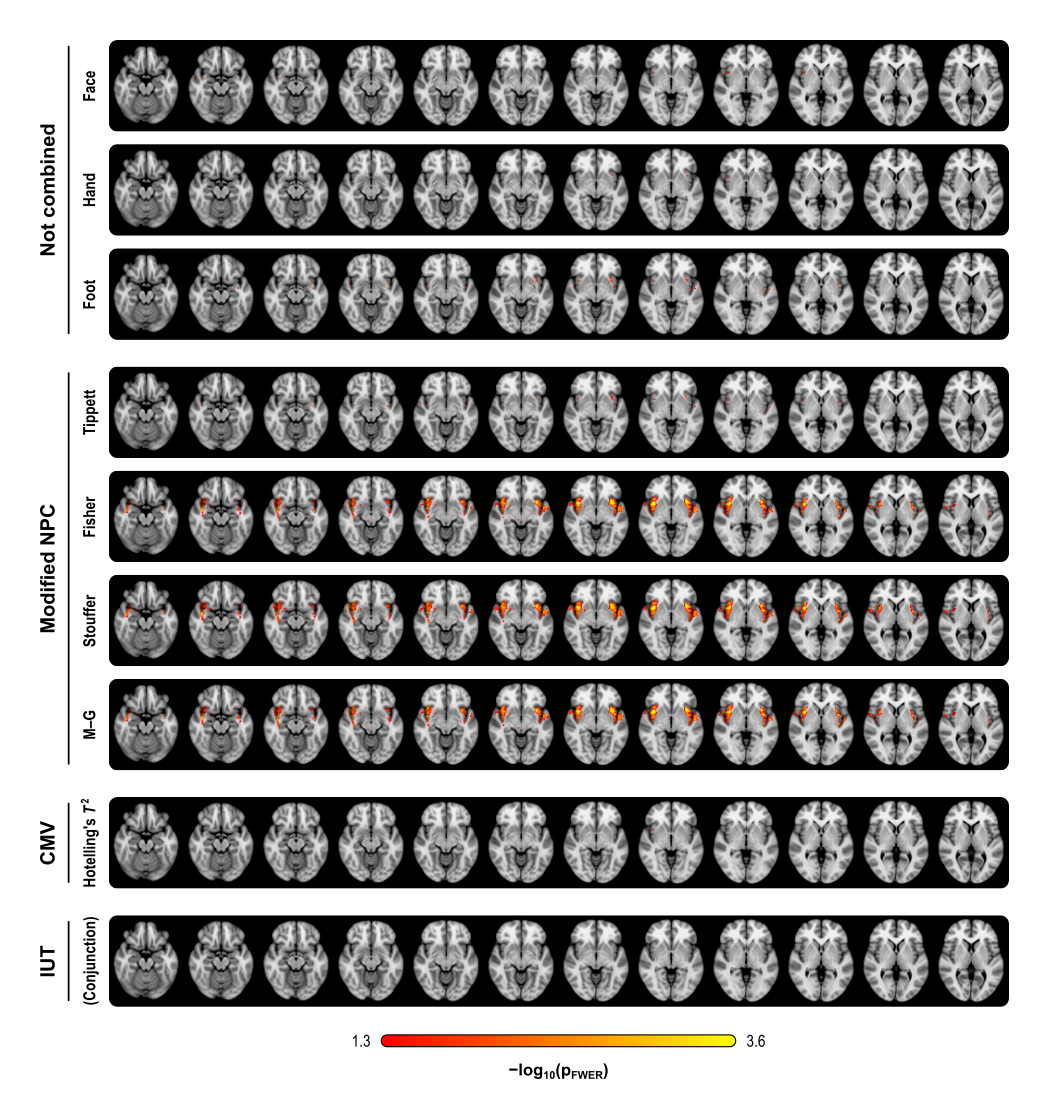
The figure below summarises the analysis of a subset of the subjects of a published FMRI study (Brooks et al, 2005) in which painful stimulation was applied to the face, hand, and foot of 12 subjects. Using permutation tests separately, no results could be identified for any of the three types of stimulation. A simple multivariate test, the Hotelling’s T2 test, even assessed using permutations, did not reveal any effect of stimulation either. The NPC results, however, suggest involvement of large portions of the anterior insula and secondary somatosensory cortex. The Fisher, Stouffer and Mudholkar–George combining functions were particularly successful in recovering a small area of activity in the midbrain and periaqueductal gray area, which would be expected from previous studies on pain, but that could not be located from the original, non-combined data.
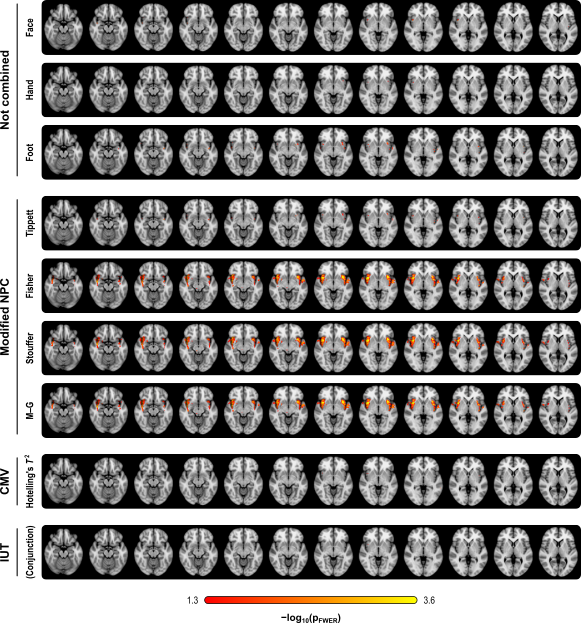
Detailed assessment of power, using variable number of modalities, and of modalities containing signal, is shown in the paper.
Combinations or conjunctions?
Combination, as done via NPC, is different than conjunctions (Nichols et al., 2005) in the following: in the combination, one seeks for aggregate significance across partial tests, without the need that any individual study is necessarily significant. In the conjunction, it is necessary that all of them, with no exception, is significant. As indicated above, the NPC forms an union-intersection test (UIT; Roy, 1953), whereas the conjunctions form an intersection-union test (IUT; Berger, 1982). The former can be said to be significant if any (or an aggregate) of the partial tests is significant, whereas the latter is significant if all the partial tests are.
Availability
The NPC, with the modifications for brain imaging, is available in the tool PALM — Permutation Analysis of Linear Models. It runs in either Matlab or Octave, and is free (GPL).
References
- Berger RL. Multiparameter hypothesis testing and acceptance sampling. Technometrics. 1982;24(4):295-300.
- Blair RC, Karniski W. An alternative method for significance testing of waveform difference potentials. Psychophysiology. 1993;30(5):518-24.
- Brooks JCW, Zambreanu L, Godinez A, Craig ADB, Tracey I. Somatotopic organisation of the human insula to painful heat studied with high resolution functional imaging. Neuroimage. 2005;27(1):201-9.
- Nichols T, Brett M, Andersson J, Wager T, Poline J-B. Valid conjunction inference with the minimum statistic. Neuroimage. 2005 Apr 15;25(3):653-60.
- Nichols T, Hayasaka S. Controlling the familywise error rate in functional neuroimaging: a comparative review. Stat Methods Med Res. 2003 Oct;12(5):419-46.
- Pantazis D, Nichols TE, Baillet S, Leahy RM. A comparison of random field theory and permutation methods for the statistical analysis of MEG data. Neuroimage. 2005;25(2):383-94.
- Pesarin F. On a nonparametric combination method for dependent permutation tests with applications. Psychother Psychosom. 1990;54:172-9.
- Pesarin F. A resampling procedure for nonparametric combination of several dependent tests. J Ital Stat Soc. 1992;1(1):87-101.
- Pesarin F, Salmaso L. Permutation Tests for Complex Data: Theory, Applications and Software. John Wiley and Sons, West Sussex, England, UK, 2010.
- Roy SN. On a Heuristic Method of Test Construction and its use in Multivariate Analysis. Ann Math Stat. 1953 Jun;24(2):220-38.
- Smith SM, Nichols TE. Threshold-free cluster enhancement: addressing problems of smoothing, threshold dependence and localisation in cluster inference. Neuroimage. 2009;44(1):83-98.
- Tippett LHC. The methods of statistics. Williams and Northgate, London, 1931.
- Westfall PH, Young SS. Resampling-Based Multiple Testing: Examples and Methods for p-Value Adjustment. John Wiley and Sons, New York, 1993.
- Winkler AM, Ridgway GR, Webster MA, Smith SM, Nichols TE. Permutation inference for the general linear model. Neuroimage. 2014;92:381-97 (Open Access).
- Winkler AM, Webster MA, Brooks JC, Tracey I, Smith SM, Nichols TE. Non-parametric combination and related permutation tests for neuroimaging. Hum Brain Mapp. 2016 Feb 5 (in press, Open Access). The Supporting Information can be browsed directly here. This paper supersedes our earlier poster presented in the 2013 OHBM conference.
Contributed to this post: Tom Nichols.


 , growing uniformly and without gaps, and we see a tank that has a serial number
, growing uniformly and without gaps, and we see a tank that has a serial number  , then clearly at least
, then clearly at least  . In that case, what would be the average value of the serial numbers of all
. In that case, what would be the average value of the serial numbers of all  , that is, the average of the first and last serial numbers.
, that is, the average of the first and last serial numbers. , our guess would be
, our guess would be  (that is, reorganizing the terms of the previous equation for
(that is, reorganizing the terms of the previous equation for  ). Note that, for one sighting, this formula guarantees that
). Note that, for one sighting, this formula guarantees that 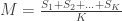 , for ordered serial numbers
, for ordered serial numbers 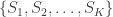 . Clearly, we can’t use the same formula, because if
. Clearly, we can’t use the same formula, because if  (say, because we have seen many small serial numbers, but just a handful of larger ones),
(say, because we have seen many small serial numbers, but just a handful of larger ones), 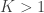 , the above formula gives invaluable insight: it shows that for such uniformly distributed data, approximately half of the tanks have serial number above
, the above formula gives invaluable insight: it shows that for such uniformly distributed data, approximately half of the tanks have serial number above 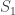 (which is
(which is 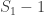 ) must be approximately the same as the (unknown) number of tanks above the highest serial number
) must be approximately the same as the (unknown) number of tanks above the highest serial number  .
. . As it is based on all
. As it is based on all  .
. . Then our best guess would be
. Then our best guess would be  .
.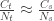 , that is, the number of cases among those who travelled (
, that is, the number of cases among those who travelled ( ) divided by the total number of people who travelled (
) divided by the total number of people who travelled (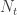 ) is expected to be approximately the same as the number of cases among those who stayed (
) is expected to be approximately the same as the number of cases among those who stayed (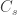 ) divided by the total number of people who stayed (live) in the city (
) divided by the total number of people who stayed (live) in the city ( ).
). people travelling out, and
people travelling out, and  staying in the city. The number of known international cases was at the time
staying in the city. The number of known international cases was at the time 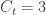 . Hence:
. Hence: cases
cases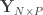 and
and 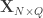 be two sets of variables over which CCA is computed. We find canonical coefficients
be two sets of variables over which CCA is computed. We find canonical coefficients 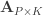 and
and 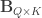 ,
, 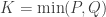 such that the canonical variables
such that the canonical variables 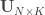 and
and  have maximal, diagonal correlation structure; this diagonal contains the ordered canonical correlations
have maximal, diagonal correlation structure; this diagonal contains the ordered canonical correlations  .
.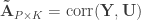 and
and  be such correlations, which are termed canonical loadings or structure coefficients. Now compute the mean square for each of the columns of
be such correlations, which are termed canonical loadings or structure coefficients. Now compute the mean square for each of the columns of 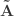 and
and 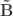 . These represent the variance extracted by the corresponding canonical variable. That is:
. These represent the variance extracted by the corresponding canonical variable. That is: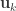 :
: 
 :
: 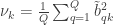
 , the usual coefficient of determination.
, the usual coefficient of determination. and
and  and
and  -th pair of canonical variables.
-th pair of canonical variables.


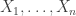 be a sequence of independent and identically distributed variables with cumulative distribution function (cdf)
be a sequence of independent and identically distributed variables with cumulative distribution function (cdf) 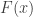 and let
and let 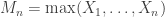 denote the maximum.
denote the maximum.
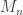 directly is problematic because as
directly is problematic because as  ,
, 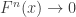 . Redefining the problem as a function of
. Redefining the problem as a function of 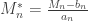 renders treatment simpler. The theorem can be stated then as: If there exist sequences of constants
renders treatment simpler. The theorem can be stated then as: If there exist sequences of constants  and
and  such that, as
such that, as 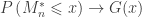
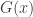 belongs to one of three “domains of attraction”:
belongs to one of three “domains of attraction”: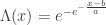 , for
, for 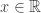 indicating that the distribution of
indicating that the distribution of  indicating that the distribution of
indicating that the distribution of 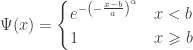 indicating that the distribution of
indicating that the distribution of 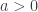 ,
,  and, for families II and III,
and, for families II and III,  . To which of the three a particular
. To which of the three a particular  . Thus, we can infer about the asymptotic properties of the maximum while having only a limited knowledge of the properties of
. Thus, we can infer about the asymptotic properties of the maximum while having only a limited knowledge of the properties of  , whereas Fisher and Tippett used
, whereas Fisher and Tippett used 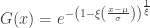
 , with parameters
, with parameters  (location),
(location),  (scale), and
(scale), and 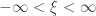 (shape). This is the generalised extreme value (GEV) family of distributions. If
(shape). This is the generalised extreme value (GEV) family of distributions. If 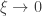 , it converges to Gumbel (type I), whereas if
, it converges to Gumbel (type I), whereas if 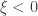 it corresponds to Fréchet (type II), and if
it corresponds to Fréchet (type II), and if  it corresponds to Weibull (type III). Inference on
it corresponds to Weibull (type III). Inference on  allows choice of a particular family for a given problem.
allows choice of a particular family for a given problem.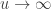 , the limiting distribution of a random variable
, the limiting distribution of a random variable  , conditional on
, conditional on 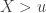 , is:
, is: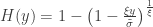
 and
and 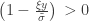 . The two parameters are the
. The two parameters are the 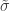 (scale). The shape corresponds to the same parameter
(scale). The shape corresponds to the same parameter 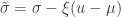 .
.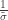 as
as ![\left[0, \tilde{\sigma}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B0%2C+%5Ctilde%7B%5Csigma%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) when
when 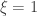 , and a Pareto distribution when
, and a Pareto distribution when  .
. , which represent distributions approximately exponential, parametters for the GPD can be estimated using at least three methods: maximum likelihood, moments, and probability-weighted moments. These are described in Hosking and Wallis (1987). For
, which represent distributions approximately exponential, parametters for the GPD can be estimated using at least three methods: maximum likelihood, moments, and probability-weighted moments. These are described in Hosking and Wallis (1987). For  and
and  be respectively the sample mean and variance. The moment estimators of
be respectively the sample mean and variance. The moment estimators of  and
and  .
.


 , is probably the most interesting. It gives a probabilistic estimate that a random gene from a given subject
, is probably the most interesting. It gives a probabilistic estimate that a random gene from a given subject  is
is  . For
. For  matrix termed kinship matrix, usually represented as
matrix termed kinship matrix, usually represented as  , that has elements
, that has elements 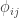 , and that can be used to model the covariance between individuals in quantitative genetics.
, and that can be used to model the covariance between individuals in quantitative genetics.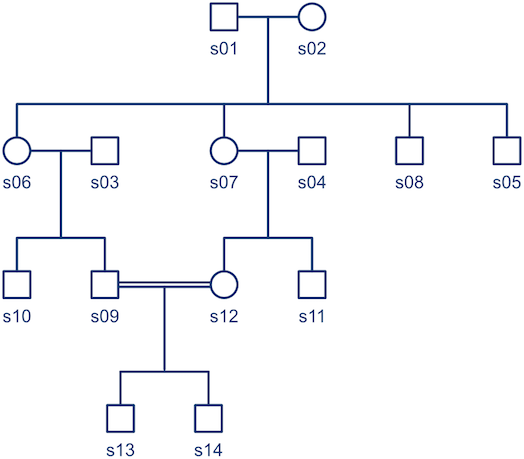
 ), is:
), is:
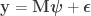
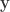 is the
is the  vector of observations,
vector of observations, 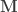 is the
is the  matrix of explanatory variables,
matrix of explanatory variables, 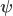 is the
is the  vector of regression coefficients, and
vector of regression coefficients, and  is the
is the  , where
, where 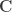 is a
is a  matrix that defines a contrast of regression coefficients, satisfying
matrix that defines a contrast of regression coefficients, satisfying 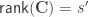 and
and  .
.
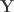 is the
is the  vector of observations,
vector of observations, 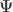 is the
is the 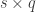 vector of regression coefficients, and
vector of regression coefficients, and  , where
, where  is a
is a  matrix that defines a contrast of observed variables, satisfying
matrix that defines a contrast of observed variables, satisfying  and
and 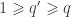 .
.
 represents a pseudo-inverse. The residuals can be computed as:
represents a pseudo-inverse. The residuals can be computed as: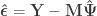
 and
and 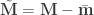 .
.
 , the multiple correlation coefficient can be computed from the
, the multiple correlation coefficient can be computed from the 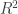 statistic as:
statistic as: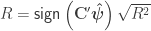
 statistic can be computed as:
statistic can be computed as: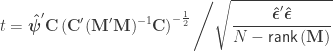
 statistic can be computed as:
statistic can be computed as: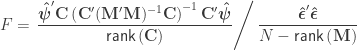
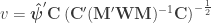
 is a diagonal matrix that has elements:
is a diagonal matrix that has elements: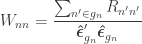
 are the
are the  diagonal elements of the residual forming matrix
diagonal elements of the residual forming matrix  , and
, and 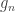 is the variance group to which the
is the variance group to which the  -th observation belongs.
-th observation belongs.
 , is given by:
, is given by: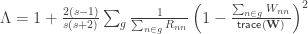

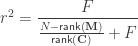
 is known, the formula can be solved for
is known, the formula can be solved for 

![\mathbf{A} = \left[\mathbf{y}\; \mathbf{M}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D+%3D+%5Cleft%5B%5Cmathbf%7By%7D%5C%3B+%5Cmathbf%7BM%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and
, and  be the inverse of the correlation matrix of the columns of
be the inverse of the correlation matrix of the columns of 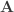 , and
, and 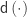 the diagonal operator, that returns a column vector with the diagonal entries of a square matrix. Then the matrix with the partial correlations is:
the diagonal operator, that returns a column vector with the diagonal entries of a square matrix. Then the matrix with the partial correlations is:
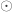 is the
is the  ” is taken elementwise (i.e., not matrix power).
” is taken elementwise (i.e., not matrix power).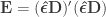 as the sums of the products of the residuals, and
as the sums of the products of the residuals, and 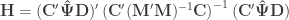 as the sums of products of the hypothesis. In fact, the original model can be modified as
as the sums of products of the hypothesis. In fact, the original model can be modified as  , where
, where 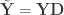 ,
, 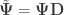 and
and  .
. , this is an univariate model, otherwise it remains multivariate, although
, this is an univariate model, otherwise it remains multivariate, although 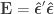 and
and  .
.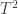 statistic can be computed as:
statistic can be computed as:


 be the eigenvalues of
be the eigenvalues of 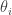 the eigenvalues of
the eigenvalues of 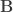 . Then:
. Then: .
. .
. .
.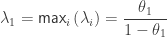 (analogous to
(analogous to  (analogous to
(analogous to  is the
is the 