

Very often we find ourselves handling large matrices and, for multiple different reasons, may want or need to reduce the dimensionality of the data by retaining the most relevant principal components. A question that arises then is how many such principal components should be retained? That is, what are the principal components that provide information that can be distinguished from variability that is indistinguishable from random noise?
One simple heuristic method is the scree plot (Cattell, 1966): one computes the singular values of the matrix, plots them in descending order, and visually looks for some kind of “elbow” (or the starting point of the “scree”) to be used as a threshold. Those singular vectors (principal components) that have corresponding singular values larger than that threshold are retained, otherwise discarded. Unfortunately, the scree test is too subjective, and worse, many realistic problems can produce matrices that have multiple such “elbows”.
Many other methods to help select the number of principal components to retain exist. Some, for example, are based on information theory, or on probabilistic formulations, or on hard thresholds related the size of the matrix or the (explained) variance from the data. In this article, the little known Wachter method (Wachter, 1976) is presented.
Let 
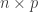



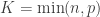

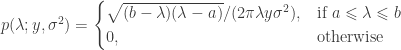
and a point mass 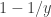

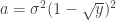
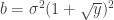

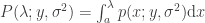
If we know the probability of finding a singular value 

The core idea of the Wachter method is to use a QQ plot of the observed singular values versus the quantiles obtained from the inverse cdf of the Marčenko–Pastur distribution, and use eventual deviations from the identity line to help finding the threshold that separates the “good” from the “unnecessary” principal components. That is, plot the eigenvalues 

The function wachter.m computes the singular values from a given observed matrix
% For reproducibility, reset the random number generator.
% Use "rand" instead of "rng" to ensure compatibility with old versions.
rand('seed',0);
% Simulate data. See Gavish and Donoho (2014) for this example.
X = diag([1.7 2.5 zeros(1,98)]) + randn(100)*sqrt(.01);
% Compute the expected and observed singular values,
% as well as the respective cumulative probabilities (p-values).
% See the help of wachter.m for syntax.
[Exp,Obs,Pexp,Pobs] = wachter(X,[],false,true);
% Log of the ratio between observed and expected p-values.
% Large values are evidence for "good" components.
P_ratio = -log10(Pobs./Pexp);
% Plot the spectrum.
subplot(1,2,1);
plot(Obs,'x:');
title('Singular values');
xlabel('index (k)');
% Construct the QQ-plot.
subplot(1,2,2);
qqplot(Exp,Obs);
title('QQ plot');
The result is:

In this example, two of the singular values can be considered “good”, and should be retained. The others can, according to this criterion, be dropped.
The function can take into account nuisance variables (provided in the 2nd argument), including intercept (for mean-centering), allows normalization of columns to unit variance, and can operate on p-values (upper tail from the density function) or on the cumulative probabilities. See the help text inside the function for usage information.
References
- Bai ZD. Methodologies in spectral analysis of large dimensional random matrices, a review. Statistica Sinica. 1999;9(3):611–77.
- Cattell RB. The scree test for the number of factors. Multivariate Behavioral Research. 1966;1(2):245–276.
- Gavish M, Donoho DL. The optimal hard threshold for singular values is 4/sqrt(3). arXiv:13055870. 2014.
- Johnstone IM. On the distribution of the largest eigenvalue in principal components analysis. The Annals of Statistics. 2001;29(2):295–327.
- Marčenko VA, Pastur LA. Distribution of eigenvalues for some sets of random matrices. Math USSR Sb. 1967;1(4):457–83.
- Wachter KW. Probability plotting points for principal components. In: Proceedings of the Ninth Interface Symposium on Computer Science and Statistics. Harvard University and Massachussetts Institute of Technology: Prindle, Weber & Schmidt; 1976. p. 299–308.
The image at the top is of the Drei Zinnen, in the Italian Alps during the Summer, in which a steep slope scattered with small stones (scree) is visible. Photo by Heinz Melion from Pixabay.

Great entry Anderson!
Quick question: At the end of the day, this is still subjective, right? Did you choose 2 components because they looked “fine” (far enough from the identity line) in the right-hand plot?
How far from the identity line is “far enough”?
Fidel
Hey Fidel,
Thanks for commenting. It’s certainly somewhat subjective though less so than, e.g., the Cattell (scree) test.
Using the -log(P_observed/P_expected) makes identifying the cutoff perhaps more objective: the late components (assumed noise) will be close to zero though with some variability around it; the earlier components (if containing signal) will have values above zero and beyond that random variability seen in the later ones.
The QQ-plot also helps in that the good components will be far from the identity line. How “far” is indeed subjective, but the -log of the ratio of P-values I think helps to make it more objective (and scriptable, without the need to actually look at the plot).
Happy to discuss more! :-)
Cheers,
Anderson
Thanks!
Sure, this is sort of more objective and more scriptable. What do you think would be a good criterion? Running the code, I always get Inf in the 2 first values of P_ratio. Would that be a good scriptable criterion?
Cheers
How about a cutoff of 0.5? It’d mean that the observed p-value would have to be roughly 1/3 of the expected or smaller to be considered “good”.
The example will always give 2 (it’s from the Donoho and Gavish paper). With different matrices it should give different results. It’s “Inf” because the observed p-values in this case are 0 (given the machine precision).