

How similar?
The degree of relationship between two related individuals can be estimated by the probability that a gene in one subject is identical by descent to the corresponding gene (i.e., in the same locus) in the other. Two genes are said to be identical by descent (ibd) if both are copies of the same ancestral gene. Genes that are not ibd may still be identical through separate mutations, and be therefore identical by state (ibs), though these will not be considered in what follows.
The coefficients below were introduced by Jacquard in 1970, in a book originally published in French, and translated to English in 1974. A similar content appeared in an article by the same author in the journal Biometrics in 1972 (see the references at the end).
Coefficients of identity
Consider a particular autosomal gene 




To each of these states 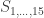


As before, to each of these states 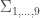
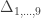
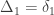
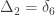

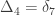




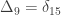
A similar method was proposed by Cotterman (1940), in his highly influential but only much later published doctoral thesis. The 

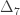



Coefficient of kinship
The above refer to probabilities of finding particular genes as identical among subjects. However, a different coefficient can be defined for random genes: the probability that a random gene from subject 
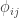

If 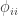


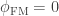
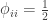
The value of 






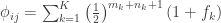
For a set of subjects, the pairwise coefficients of kinship 

Coefficient of inbreeding
The coefficient of inbreeding 


Note that all these coefficients are based on probabilities, but it is now possible to identify the actual presence of a particular gene using marker data. Also note that while the illustrations above suggest application to livestock, the same applies to studies of human populations.
Some particular cases
The computation of the above coefficients can be done using algorithms, and are done automatically by software that allow analyses of pedigree data, such as solar. Some common particular cases are shown below:
| Relationship | 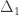 |
 |
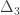 |
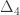 |
 |
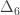 |
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|
| Self |  |
|
|
|
|
|
 |
|
|
|
| Parent-offspring | |
|
|
|
|
|
|
|
|
 |
| Half sibs | |
|
|
|
|
|
|
|
|
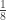 |
| Full sibs/dizygotic twins | |
|
|
|
|
|
|
|
|
|
| Monozygotic twins | |
|
|
|
|
|
|
|
|
|
| First cousins | |
|
|
|
|
|
|
|
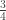 |
 |
| Double first cousins | |
|
|
|
|
|
|
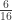 |
 |
|
| Second cousins | |
|
|
|
|
|
|
|
 |
 |
| Uncle-nephew | |
|
|
|
|
|
|
|
|
|
| Offspring of sib-matings | |
 |
|
|
|
|
 |
 |
|
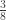 |
References
- Cotterman C. A calculus for statistico-genetics. 1940. PhD Thesis. Ohio State University.
- Jacquard, A. Structures génétiques des populations. Masson, Paris, France, 1970, later translated and republished as Jacquard, A. The genetic structure of populations. Springer, Heidelberg, 1974.
- Jacquard A. Genetic information given by a relative. Biometrics. 1972;28(4):1101-1114.
The photograph at the top (sheep) is in public domain.

Pingback: Understanding the kinship matrix | Brainder.
Pingback: Variance components in genetic analyses | Brainder.
The genetic structure of any individual is composed of the combination DNA of his parents. Variation from generation to generation is accounted for by the technicalities of mating, but a given gene in two individuals can be identified as an exact copy of a gene from a common ancestor. Or it can be one that is there from the fact of being present in either parental hierarchy. Does this affect its function in any way ? In what way is it significant? How many generations back can an identical gene be traced to a common ancestor. Please help me here. It seems to me this is significant as evidence of the truth of Intelligent Design due to the possibility of a common gene being traceable right back to pre-physiological existence
Hi John,
Thanks for commenting. Are you referring to the definitions of IBD and IBS? These are relevant insofar as we discuss population genetics, whereby it in some cases matter that identicality of a gene is due to descent, as opposed to state. A high mutation rate (not typical) would affect the computations used for variance partitioning. One could argue that this is a weakness of this particular method. It is, indeed. However, these methods were developed in the 1970’s when no genotyping was readily available. But even today, the method remains remarkably robust, and even though it may be considered approximate and based on assumptions, these assumptions do by and large hold.
Having said that, no, it does not affect function as far as we know. That is, being IBD or IBS are for all practical purposes equivalent.
Finally note that the article is about genes and loci, not entire chromosomes. Even with a low mutation rate, genes will mutate given sufficient amount of time.
Thanks again!
All the best,
Anderson
Hi Anderson,
Thank you for writing this article! Your language and use of diagrams have really helped me understand these concepts, especially Jacquards Coefficients of Identity for which I’ve read about in many papers but never been able to grasp as clearly as I have now. Truly, thank you.
I hope you don’t mind if ask, what is the difference between the Coefficient of Kinship and the Coefficient of Relatedness (r)? I understand the that r = 2θ but I’m not sure why, and the definitions provided by Blouin (2003) sound very similar to me: “The coefficient of consanguinity (also coefficient of kinship) is the probability that two alleles, one chosen randomly from two individuals, are identical by descent… The relatedness between two individuals, r, (also coefficient of relatedness) can be interpreted as the expected fraction of alleles that are shared identical by descent”. If you can help me understand the difference between these two concepts it will help me greatly. Thank you for your time!!
Hi Serina,
They should converge to the same (absent inbreeding) but the definitions differ: one refers to the probability that a random allele is shared IBD between individuals, the other is the share (fraction among all alleles) that are IBD among individuals. The former is based on expectations, and hold for any particular allele; the latter is empirical and based on markers that could span the whole genome. The former requires only knowledge of familial relationships; the latter uses molecular methods. The former is discrete (varying in powers of 1/2^n); the latter is continuous.
I agree it’s confusing… but hope this helps!
All the best,
Anderson
Hi Anderon,
You are brilliant!! Thank you, you’ve helped me understand more in this answer than literally hours of reading was able too! I’m enjoying reading the rest of your blog as well and I can’t express how much I appreciate your contributions to science and helping others in this way. It really means a lot. Have a wonderful week!
Yours gratefully,
Serina
Thanks for the feedback!
Hi great reading your posst