

How similar?
The degree of relationship between two related individuals can be estimated by the probability that a gene in one subject is identical by descent to the corresponding gene (i.e., in the same locus) in the other. Two genes are said to be identical by descent (ibd) if both are copies of the same ancestral gene. Genes that are not ibd may still be identical through separate mutations, and be therefore identical by state (ibs), though these will not be considered in what follows.
The coefficients below were introduced by Jacquard in 1970, in a book originally published in French, and translated to English in 1974. A similar content appeared in an article by the same author in the journal Biometrics in 1972 (see the references at the end).
Coefficients of identity
Consider a particular autosomal gene 




To each of these states 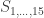


As before, to each of these states 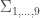
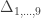
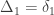
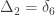

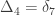




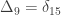
A similar method was proposed by Cotterman (1940), in his highly influential but only much later published doctoral thesis. The 

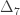



Coefficient of kinship
The above refer to probabilities of finding particular genes as identical among subjects. However, a different coefficient can be defined for random genes: the probability that a random gene from subject 
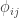

If 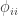


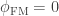
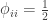
The value of 






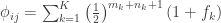
For a set of subjects, the pairwise coefficients of kinship 

Coefficient of inbreeding
The coefficient of inbreeding 


Note that all these coefficients are based on probabilities, but it is now possible to identify the actual presence of a particular gene using marker data. Also note that while the illustrations above suggest application to livestock, the same applies to studies of human populations.
Some particular cases
The computation of the above coefficients can be done using algorithms, and are done automatically by software that allow analyses of pedigree data, such as solar. Some common particular cases are shown below:
| Relationship |  |
 |
 |
 |
 |
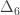 |
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|
| Self |  |
|
|
|
|
|
 |
|
|
|
| Parent-offspring | |
|
|
|
|
|
|
|
|
 |
| Half sibs | |
|
|
|
|
|
|
|
|
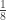 |
| Full sibs/dizygotic twins | |
|
|
|
|
|
|
|
|
|
| Monozygotic twins | |
|
|
|
|
|
|
|
|
|
| First cousins | |
|
|
|
|
|
|
|
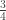 |
 |
| Double first cousins | |
|
|
|
|
|
|
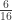 |
 |
|
| Second cousins | |
|
|
|
|
|
|
|
 |
 |
| Uncle-nephew | |
|
|
|
|
|
|
|
|
|
| Offspring of sib-matings | |
 |
|
|
|
|
 |
 |
|
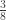 |
References
- Cotterman C. A calculus for statistico-genetics. 1940. PhD Thesis. Ohio State University.
- Jacquard, A. Structures génétiques des populations. Masson, Paris, France, 1970, later translated and republished as Jacquard, A. The genetic structure of populations. Springer, Heidelberg, 1974.
- Jacquard A. Genetic information given by a relative. Biometrics. 1972;28(4):1101-1114.
The photograph at the top (sheep) is in public domain.
