
Coefficients to assess the genetic resemblance between individuals were presented in the last post. Among these, the coefficient of kinship, 



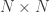

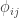
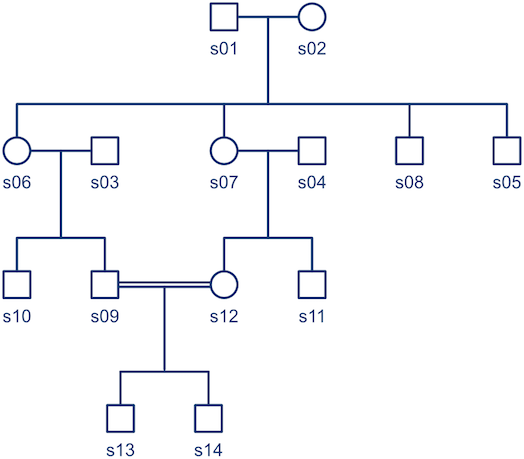
Consider the pedigree in the figure below, consisted of 14 subjects:
The corresponding kinship matrix, already multiplied by two to indicate expected covariances between subjects (i.e., 
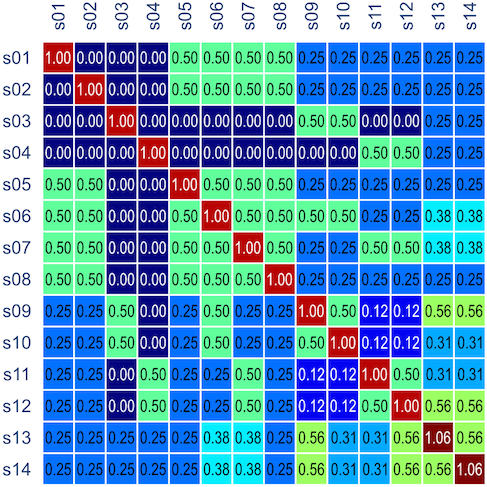
Note that the diagonal elements can have values above unity, given the consanguineous mating in the family (between s09 and s12, indicated by the double line in the pedigree diagram).
In the next post, details on how the kinship matrix can be used investigate heritabilities, genetic correlations, and to perform association studies will be presented.

Pingback: Genetic resemblance between relatives | Brainder.
Pingback: Variance components in genetic analyses | Brainder.
do you know why diagonal elements can have values above unity? I knowed correlation coefficient is between 0 and 1.
Hi Lee,
There is a consanguineous mating between s09 and s12, such that the expected covariance between the offspring of this relationship other subjects in the pedigree is higher than for self. The explanation for these coefficients is in this earlier post: https://brainder.org/2015/06/13/genetic-resemblance-between-relatives/
Hope this helps!
All the best,
Anderson