Binary file formats are faster to read and occupy less space for storage. However, when developing tools or when analysing data using non-standard methods, ascii files are easier to treat, and allow certain errors to be spotted immediately. Working with ascii files offer a number of advantages in these circumstances: the content of the files are human readable, meaning that there is no need for any special program other than perhaps a simple text editor, and can be manipulated easily with tools as sed or awk. It should be noted though, that while binary files require attention with respect to endianess and need some metadata to be correctly read, ascii need proper attention to end-of-line characters, that vary according to the operating system.
In articles to be posted soon I hope to share some tools to analyse and visualise brain imaging data. To use these tools, the files must be in ascii format. Each of these formats is discussed below and an example is given for a simple octahedron.

FreeSurfer surface (*.asc | suggested: *.srf)
FreeSurfer natively saves its surface files in binary form. The command mris_convert allows conversion to ascii format. The file extension is *.asc. This extension, however, is ambiguous with the curvature format (see below), reason for which a recommendation is to rename from *.asc to *.srf immediately after conversion.
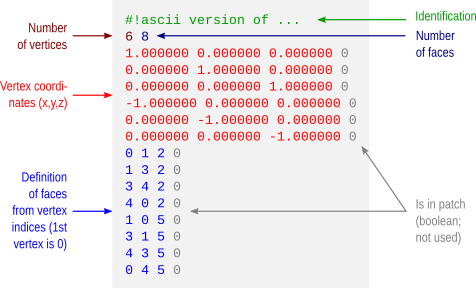
The *.asc/*.srf format has a structure as described below. This format does not allow storing normals, colors, materials, multiple objects or textures. Just simple geometry.
FreeSurfer curvature (*.asc | suggested: *.dpv)
A curvature file contains a scalar value assigned to each vertex. This file format does not store the geometry of the surface and, in binary form, a curvature file simply contains one scalar per vertex. In ascii format, the vertex coordinates are also saved, but not how these vertices relate to define faces and the overall geometry.
Like with the FreeSurfer surface files, curvature files in ascii format also have the extension *.asc. To avoid confusion, it is suggested to rename from *.asc to *.dpv (data-per-vertex) immediately after conversion.

Facewise data (*.dpf)
This is not a native format from FreeSurfer, but a modification over the ascii curvature file described above. The file stores a scalar value per face, i.e. data-per-face (dpf) and, instead of saving vertex coordinates as with the *.dpv files, here the vertex indices that define the faces are saved. It is done like so because if both *.dpv and *.dpf files are present for a given geometric object, the object can be reconstructed with very little manipulation using simply awk. Currently there is no binary equivalent format.
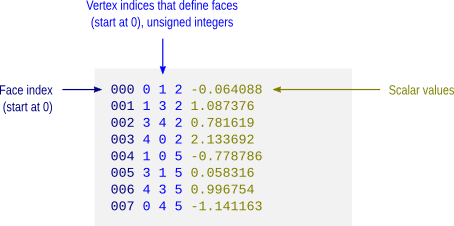
VTK polygonal data (*.vtk)
A number of file formats have been developed over the years for use with the Visualization Toolkit (vtk). Some of these formats are now considered as “legacy” and are being phased out in favour of xml formats. Despite this, they are still used by a number of applications, such as fsl/first. The octahedron above in vtk polygonal data (polydata) format would have a structure as depicted below.

Wavefront Object (*.obj)
Wavefront Object files have a very simple structure, yet are powerful to allow definition of textures, normals and different materials. The format is supported by a variety of different graphic applications. The octahedron above would have a file structure as shown below.

The example does not show colors. However, it is possible to assign a material to each face, and materials contain their own color. These materials are typically stored in a separate file, a Materials Library, with extension *.mtl. An example for the same octahedron, both the object file and its associated materials library, is here: octa-color.obj and octa-color.mtl.

Many computer graphics software, however, limit the number of colors per object to a relatively small number, as 16 or 32. Blender, however, allows 32767 colors per object, a comfortable space for visualization of complex images, such as brain maps.
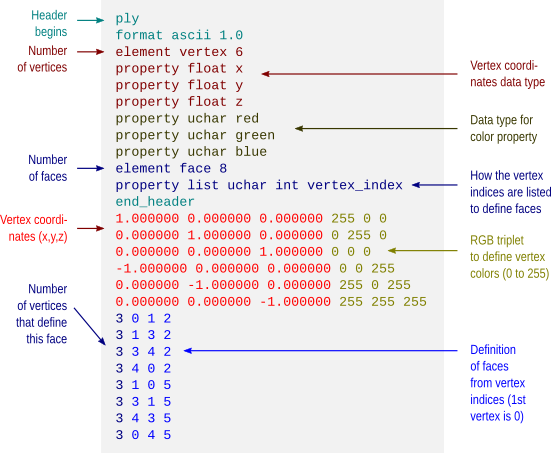
Stanford Polygon (*.ply)
The Stanford Polygon file allows not only the geometry to be stored, but also allow colours, transparency, confidence intervals and other properties to be assigned at each vertex. Again, the octahedron would have a file structure as:

This format also allows color attributes to be assigned to each vertex, as shown below.
The resulting object would then look like:

Batch conversion
Conversion between FreeSurfer formats can be done using mris_convert. A script to batch convert all FreeSurfer surface and curvature files from binary format to ascii is available here: subj2ascii. Before running, make sure FreeSurfer is correctly configured, that the variable SUBJECTS_DIR has been correctly set, and that you have writing permissions to this directory. Execute the script with no arguments to get usage information. The outputs (*.srf and *.dpv) are saved in a directory called ascii inside the directory of the subject. For many subjects, use a for-loop in the shell.
For more information
- A description of the FreeSurfer file formats is available here.
- A description of the different vtk (legacy and current) is available here.
- Specification of the Wavefront obj format is here. Material library files are described here.
- A description of the Stanford ply format is here.
Update — 28.May.2012: A script to convert from FreeSurfer .asc/.srf to .obj is here.
Update — 26.Jul.2013: This post was just updated to include examples of color formats.

 hypotheses,
hypotheses,  based on their respective p-values,
based on their respective p-values,  . Consider that a fraction
. Consider that a fraction  of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,
of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,  and denote
and denote  the hypothesis corresponding to
the hypothesis corresponding to  . Let
. Let  be the largest
be the largest  for which
for which  . Then reject all
. Then reject all 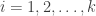 . The constant
. The constant  is not in the original publication, and appeared in
is not in the original publication, and appeared in 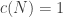 or
or  . The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by
. The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by  . This formulation, however, has problems, as discussed next.
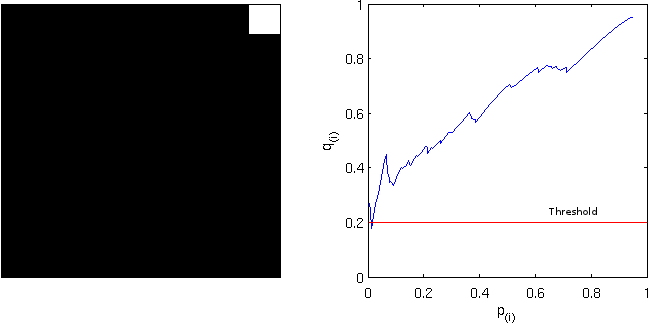
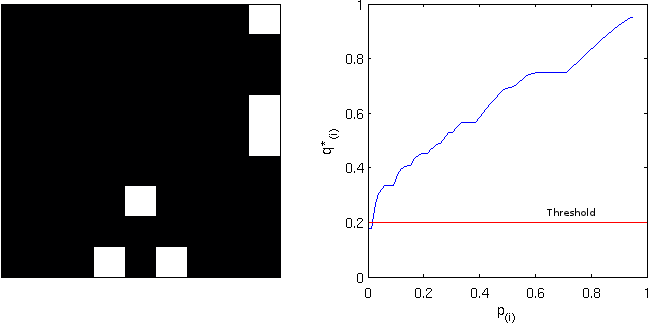
. This formulation, however, has problems, as discussed next. is not a monotonic function of
is not a monotonic function of  be the FDR-adjusted value for
be the FDR-adjusted value for  , where
, where 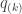 is the FDR-corrected as defined above. That’s just it!
is the FDR-corrected as defined above. That’s just it!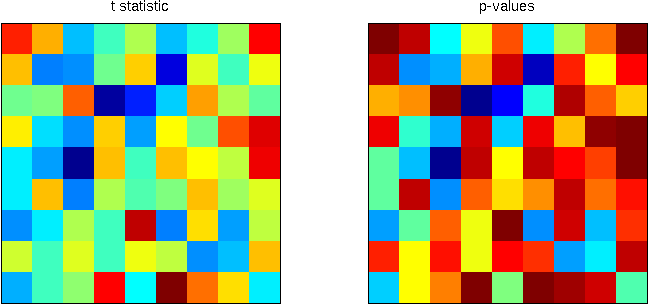
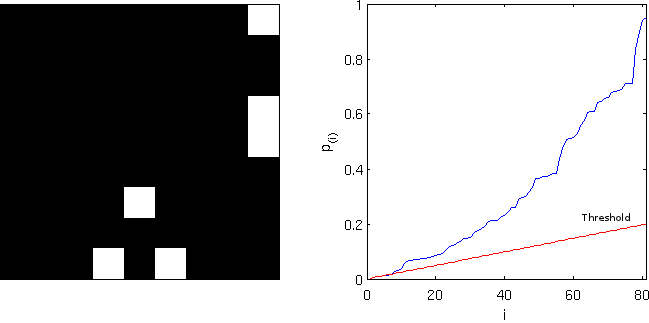
 , and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.
, and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.