
In a previous post, all commonly used univariate and multivariate test statistics used with the general linear model (GLM) were presented. Here an alternative formulation for one of these statistics, the Pillai’s trace (Pillai, 1955, references at the end), commonly used in MANOVA and MANCOVA tests, is presented.
We begin with a multivariate general linear model expressed as:
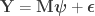
where 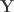
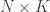


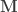

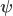



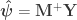

The null hypothesis, and a simplification
One is generally interested in testing the null hypothesis that a contrast of regression coefficients is equal to zero, i.e., 
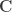
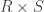


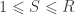






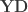
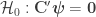
Model partitioning
It is useful to consider a transformation of the model into a partitioned one:
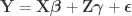
where 

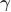

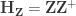


Such partitioning is not unique, and schemes can be as simple as separating apart the columns of ![\left[ \mathbf{X} \; \mathbf{Z} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cmathbf%7BX%7D+%5C%3B+%5Cmathbf%7BZ%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\boldsymbol{\psi} = \left[ \boldsymbol{\beta}' \; \boldsymbol{\gamma}' \right]'](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%5Cpsi%7D+%3D+%5Cleft%5B+%5Cboldsymbol%7B%5Cbeta%7D%27+%5C%3B+%5Cboldsymbol%7B%5Cgamma%7D%27+%5Cright%5D%27&bg=ffffff&fg=333333&s=0&c=20201002)
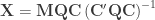



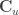

![[\mathbf{C} \; \mathbf{C}_u]](https://s0.wp.com/latex.php?latex=%5B%5Cmathbf%7BC%7D+%5C%3B+%5Cmathbf%7BC%7D_u%5D&bg=ffffff&fg=333333&s=0&c=20201002)
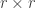
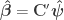

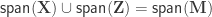
Another partitioning scheme, derived by Ridgway (2009), defines 


The usual multivariate statistics
For the multivariate statistics, define generically:
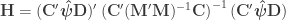
as the sums of products explained by the model (hypothesis) and:
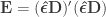
as the sums of the products of the residuals, i.e., that remain unexplained. With the simplification to the original model that redefined 
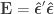
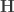
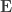

More simplifications
With the partitioning, other simplifications are possible:
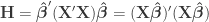
Recalling that 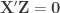

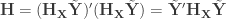
The unexplained sums of products can be written in a similar manner:

The term 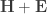

Using the property that the trace of a product is invariant to a circular permutation of the factors, Pillai’s statistic can then be written as:

The final, alternative form
Using sigular value decomposition we have 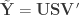

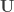

The SVD transformation is useful for languages or libraries that offer a fast implementation. Otherwise, using a pseudoinverse yields the same result, perhaps only slightly slower. In this case, 
Importance
If we define 



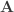

Availability
This simplification is available in PALM, for use with imaging and non-imaging data, using Pillai’s trace itself, or a modification that allows inference on univariate statistics. As of today, this option is not yet documented, but should become openly available soon.
References
- Kazi-Aoual F, Hitier S, Sabatier R, Lebreton J-D. Refined approximations to permutation tests for multivariate inference. Comput Stat Data Anal. 1995;20(94):643–56.
- Mardia KV. The Effect of Nonnormality on some multivariate tests and robustness to nonnormality in the linear model. Biometrika. 1971;58(1):105–21.
- Minas C, Montana G. Distance-based analysis of variance: Approximate inference. Stat Anal Data Min. 2014;7(6):450–70.
- Pillai KCS. Some New test criteria in multivariate analysis. Ann Math Stat. 1955;26(1):117–21.
- Ridgway GR. Statistical analysis for longitudinal MR imaging of dementia. PhD Thesis. University College London, 2009.
- Smith SM, Jenkinson M, Beckmann CF, Miller K, Woolrich M. Meaningful design and contrast estimability in FMRI. Neuroimage. 2007;34(1):127–36.
- Winkler AM, Ridgway GR, Webster MA, Smith SM, Nichols TE. Permutation inference for the general linear model. Neuroimage. 2014;92:381–97.
Update: 20.Jan.2016: A slight simplification was applied to the formulas above so as to make them more elegant and remove some redundancy. The result is the same.
