

Can you tell?
The now famous story is that in an otherwise unremarkable summer afternoon in Cambridge in the 1920’s, a group of friends eventually discussed about the claims made by one of the presents about her abilities on discriminating whether milk was poured first or last when preparing a cup of tea with milk. One of the presents was Ronald Fisher, and the story, along with a detailed description of how to conduct a simple experiment to test the claimed ability, and how to obtain an exact solution, was presented at length in the Chapter 2 of his book The Design of Experiments, a few lines of which are quoted below:
A lady declares that by tasting a cup of tea made with milk she can discriminate whether the milk or the tea infusion was first added to the cup. We will consider the problem of designing an experiment by means of which this assertion can be tested. […] [It] consists in mixing eight cups of tea, four in one way and four in the other, and presenting them to the subject for judgment in a random order. The subject has been told in advance of that the test will consist, namely, that she will be asked to taste eight cups, that these shall be four of each kind […]. — Fisher, 1935.
There are 

The lady in question eventually answered correctly six out of the eight trials. The results can be assembled in a 2 by 2 contingency table:
| True order: | Total (margin) | |||
|---|---|---|---|---|
| Tea first | Milk first | |||
| Lady’s Guesses: | Tea first | 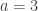 |
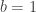 |
 |
| Milk first |  |
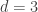 |
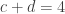 |
|
| Total (margin) | 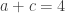 |
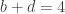 |
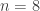 |
|
With these results, what should be concluded about the ability of the lady in discriminating whether milk or tea was poured first? It is not possible to prove that she would never be wrong, because if a sufficiently large number of cups of tea were offered, a single failure would disprove such hypothesis. However, a test that she is never right can be disproven, with a certain margin of uncertainty, given the number of cups offered.
Solution using Fisher’s exact method
Fisher presented an exact solution for this experiment. It is exact in the sense that it allows an exact probability to be assigned to each of the possible outcomes. The probability can be calculated as:
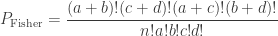
For the particular configuration of the contingency table above, the probability is 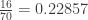
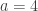





Thus, if the lady is not able to discriminate whether tea or milk was poured first, the chance of observing a result at least as favourable towards her claim would be 0.24286, i.e., about 24%.
If from the outset we were willing to consider a significance level 0.05 (5%) as an informal rule to disprove the null hypothesis, we would have considered the p-value = 0.24286 as non-significant. This p-value is exact, a point that will become more clear below, in the section about permutation tests.
Using the hypergeometric distribution directly
The above process can become laborious for experiments with larger number of trials. An alternative, but equivalent solution, is to appeal directly to the hypergeometric distribution. The probability mass function (pmf) of this distribution can be written as a function the parameters of the contingency table as:

The pmf is equivalent to Fisher’s exact formula to compute the probability of a particular configuration. The cumulative density function, which is conditional on the margins being fixed, is:
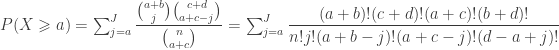
where 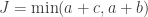
Solution using Pearson’s  method
method
Much earlier than the tea situation described above, Karl Pearson had already considered the problem of inference in contingency tables, having proposed a test based on a

where 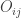



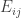



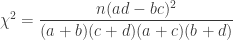
A p-value can be computed from the 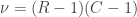
Under the null, we can expect a value equal to 2 in each of the 2 cells, that is, the lady would for each cup have a 50:50 chance of answering correctly. For the original tea tasting experiment, Pearson’s method give quite inaccurate results: 
Improvement using Yates’ continuity correction
To solve the above well-known issue with small quantities, Yates (1934) proposed a correction, such that the test statistic becomes:
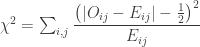
Applying this correction to the original tea experiment gives 
Equivalence of Fisher’s exact test and permutation tests
The method proposed by Fisher corresponds to a permutation test. Let 
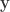



Under the null hypothesis that the lady cannot discriminate, the binary values in 
Note that the strategy using the GLM can be used even if both variables
Why not a binomial test?
The binomial test could be considered if the lady did not know in advance that there were 4 cups of each mixture order. Since she knew (so the two margins of the table are fixed), each cup was not independent from each other, and her possible answers had to be constrained by answers previously given. The binomial test assumes independence, thus, is not an option for this analysis.
Relevance
Using this simple experiment, Fisher established most of the fundamental principles for hypothesis testing, which contributed to major advances across biological and physical sciences. A careful read of the original text shows a precise use of terms, in a concise and unambiguous presentation, in contrast with many later and more verbose textbooks that eventually hid from readers most of the fundamental principles.
References
- Fisher, R. A. The Design of Experiments. Oliver and Boyd, Edinburgh, 1935.
- Pearson K. X. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Philos Mag Ser 5. 1900 Jul;50(302):157–75.
- Yates F. Contingency Tables Involving Small Numbers and the Chi^2 test. Suppl to J R Stat Soc. 1934;1(2):217–35.
The photograph at the top (tea with milk) is in public domain.


 subjects,
subjects,  traits,
traits,  covariates and
covariates and  variance components,
variance components, 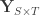 are the observed trait values for each subject,
are the observed trait values for each subject,  is a matrix of covariates,
is a matrix of covariates, 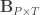 is a matrix of unknown covariates’ weights, and
is a matrix of unknown covariates’ weights, and  are the residuals after the covariates have been taken into account.
are the residuals after the covariates have been taken into account. of
of  are assumed to follow a multivariate normal distribution
are assumed to follow a multivariate normal distribution  , where
, where  is the between-subject covariance matrix. The elements of each row
is the between-subject covariance matrix. The elements of each row  of
of 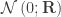 , where
, where  is the between-trait covariance matrix. Both
is the between-trait covariance matrix. Both 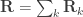 and
and 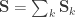 . For a discussion on these equalities, see Eisenhart (1947) [see references at the end].
. For a discussion on these equalities, see Eisenhart (1947) [see references at the end]. be the stacked vector of traits,
be the stacked vector of traits,  is the matrix of covariates,
is the matrix of covariates,  the vector with the covariates’ weights,
the vector with the covariates’ weights,  the residuals after the covariates have been taken into account, and
the residuals after the covariates have been taken into account, and 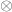 represent the
represent the 
 is assumed to follow a multivariate normal distribution
is assumed to follow a multivariate normal distribution  , where
, where  can be seen as the sum of
can be seen as the sum of 
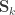 can be modelled as correlation matrices. The associated scalars are absorbed into the (to be estimated)
can be modelled as correlation matrices. The associated scalars are absorbed into the (to be estimated)  .
. ![\mathbf{R} = \left[ \begin{array}{ccc} \mathsf{Var}(\upsilon_1) & \cdots & \mathsf{Cov}(\upsilon_1,\upsilon_T) \\ \vdots & \ddots & \vdots \\ \mathsf{Cov}(\upsilon_T,\upsilon_1) & \cdots & \mathsf{Var}(\upsilon_T) \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BR%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29+%26+%5Ccdots+%26+%5Cmathsf%7BCov%7D%28%5Cupsilon_1%2C%5Cupsilon_T%29+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cmathsf%7BCov%7D%28%5Cupsilon_T%2C%5Cupsilon_1%29+%26+%5Ccdots+%26+%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 -th component:
-th component:![\mathbf{R}_k = \left[ \begin{array}{ccccc} \mathsf{Var}_k(\upsilon_1) & \cdots & \mathsf{Cov}_k(\upsilon_1,\upsilon_T) \\ \vdots & \ddots & \vdots \\ \mathsf{Cov}_k(\upsilon_T,\upsilon_1) & \cdots & \mathsf{Var}_k(\upsilon_T) \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BR%7D_k+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29+%26+%5Ccdots+%26+%5Cmathsf%7BCov%7D_k%28%5Cupsilon_1%2C%5Cupsilon_T%29+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cmathsf%7BCov%7D_k%28%5Cupsilon_T%2C%5Cupsilon_1%29+%26+%5Ccdots+%26+%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 as:
as:![\mathbf{\mathring{R}} = \left[ \begin{array}{ccc} \frac{\mathsf{Var}(\upsilon_1)}{\mathsf{Var}(\upsilon_1)} & \cdots & \frac{\mathsf{Cov}(\upsilon_1,\upsilon_T)}{\left(\mathsf{Var}(\upsilon_1)\mathsf{Var}(\upsilon_T)\right)^{1/2}} \\ \vdots & \ddots & \vdots \\ \frac{\mathsf{Cov}(\upsilon_1,\upsilon_T)}{\left(\mathsf{Var}(\upsilon_1)\mathsf{Var}(\upsilon_T)\right)^{1/2}} & \cdots & \frac{\mathsf{Var}(\upsilon_T)}{\mathsf{Var}(\upsilon_T)} \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5Cmathring%7BR%7D%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Cfrac%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%7D%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BCov%7D%28%5Cupsilon_1%2C%5Cupsilon_T%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%5Cright%29%5E%7B1%2F2%7D%7D+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cfrac%7B%5Cmathsf%7BCov%7D%28%5Cupsilon_1%2C%5Cupsilon_T%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%5Cright%29%5E%7B1%2F2%7D%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%7D%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbf{\mathring{R}}_k = \left[ \begin{array}{ccc} \frac{\mathsf{Var}_k(\upsilon_1)}{\mathsf{Var}(\upsilon_1)} & \cdots & \frac{\mathsf{Cov}_k(\upsilon_1,\upsilon_T)}{\left(\mathsf{Var}(\upsilon_1)\mathsf{Var}(\upsilon_T)\right)^{1/2}} \\ \vdots & \ddots & \vdots \\ \frac{\mathsf{Cov}_k(\upsilon_T,\upsilon_1)}{\left(\mathsf{Var}(\upsilon_T)\mathsf{Var}(\upsilon_1)\right)^{1/2}} & \cdots & \frac{\mathsf{Var}_k(\upsilon_T)}{\mathsf{Var}(\upsilon_T)} \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5Cmathring%7BR%7D%7D_k+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Cfrac%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29%7D%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BCov%7D_k%28%5Cupsilon_1%2C%5Cupsilon_T%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%5Cright%29%5E%7B1%2F2%7D%7D+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cfrac%7B%5Cmathsf%7BCov%7D_k%28%5Cupsilon_T%2C%5Cupsilon_1%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%5Cmathsf%7BVar%7D%28%5Cupsilon_1%29%5Cright%29%5E%7B1%2F2%7D%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29%7D%7B%5Cmathsf%7BVar%7D%28%5Cupsilon_T%29%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
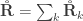 holds. The diagonal elements of
holds. The diagonal elements of  may receive particular names, e.g., heritability, environmentability, dominance effects, shared enviromental effects, etc., depending on what is modelled in the corresponding
may receive particular names, e.g., heritability, environmentability, dominance effects, shared enviromental effects, etc., depending on what is modelled in the corresponding 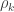 that correspond, e.g. to the genetic or environmental correlation. These off-diagonal elements are instead the signed
that correspond, e.g. to the genetic or environmental correlation. These off-diagonal elements are instead the signed  when
when 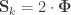 , or their
, or their  -equivalent for other variance components (see below). In this particular case, they can also be called “bivariate heritabilities” (Falconer and MacKay, 1996). A matrix
-equivalent for other variance components (see below). In this particular case, they can also be called “bivariate heritabilities” (Falconer and MacKay, 1996). A matrix  that contains these correlations
that contains these correlations ![\mathbf{\breve{R}}_k = \left[ \begin{array}{ccc} \frac{\mathsf{Var}_k(\upsilon_1)}{\mathsf{Var}_k(\upsilon_1)} & \cdots & \frac{\mathsf{Cov}_k(\upsilon_1,\upsilon_T)}{\left(\mathsf{Var}_k(\upsilon_1)\mathsf{Var}_k(\upsilon_T)\right)^{1/2}} \\ \vdots & \ddots & \vdots \\ \frac{\mathsf{Cov}_k(\upsilon_T,\upsilon_1)}{\left(\mathsf{Var}_k(\upsilon_T)\mathsf{Var}_k(\upsilon_1)\right)^{1/2}} & \cdots & \frac{\mathsf{Var}_k(\upsilon_T)}{\mathsf{Var}_k(\upsilon_T)} \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5Cbreve%7BR%7D%7D_k+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Cfrac%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29%7D%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BCov%7D_k%28%5Cupsilon_1%2C%5Cupsilon_T%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29%5Cright%29%5E%7B1%2F2%7D%7D+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cfrac%7B%5Cmathsf%7BCov%7D_k%28%5Cupsilon_T%2C%5Cupsilon_1%29%7D%7B%5Cleft%28%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29%5Cmathsf%7BVar%7D_k%28%5Cupsilon_1%29%5Cright%29%5E%7B1%2F2%7D%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29%7D%7B%5Cmathsf%7BVar%7D_k%28%5Cupsilon_T%29%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 , the coefficient of familial relationship between subjects, and
, the coefficient of familial relationship between subjects, and 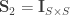 . In this case, the
. In this case, the  represent the heritability (
represent the heritability ( ) for each trait
) for each trait  contains
contains  , the environmentability. The off-diagonal elements of
, the environmentability. The off-diagonal elements of  are the off-diagonal elements of
are the off-diagonal elements of 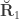 , whereas the off-diagonal elements of
, whereas the off-diagonal elements of 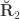 are
are 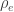 , the environmental correlations between traits. In this particular case, the components of
, the environmental correlations between traits. In this particular case, the components of 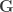 and
and 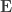 covariance matrices as in Almasy et al (1997).
covariance matrices as in Almasy et al (1997).
 and rearranging the terms gives:
and rearranging the terms gives: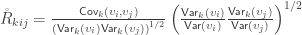
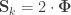 , the above reduces to
, the above reduces to  , which is the signed version of
, which is the signed version of  when
when 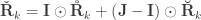
 is a matrix of ones,
is a matrix of ones,  is the identity, both of size
is the identity, both of size 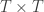 , and
, and 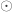 is the
is the 


 is the number of observations on the stacked vector
is the number of observations on the stacked vector  , although inefficient and inappropriate for hypothesis testing, can be obtained with ordinary least squares (OLS).
, although inefficient and inappropriate for hypothesis testing, can be obtained with ordinary least squares (OLS).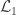 ), the loglikelihood of a model in which the parameters being tested are constrained to zero, the null model (
), the loglikelihood of a model in which the parameters being tested are constrained to zero, the null model (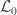 ). The statistic is given by
). The statistic is given by  (Wilks, 1938), which here is asymptotically distributed as a 50:50 mixture of a
(Wilks, 1938), which here is asymptotically distributed as a 50:50 mixture of a  and
and 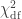 distributions, where df is the number of parameters being tested and free to vary in the unconstrained model (Self and Liang, 1987). From this distribution the p-values can be obtained.
distributions, where df is the number of parameters being tested and free to vary in the unconstrained model (Self and Liang, 1987). From this distribution the p-values can be obtained.