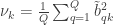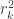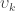It’s so often that we find ourselves in the need to quickly compute a statistic for a certain dataset, but finding the formulas is not always direct. Using a statistical software is helpful, but it often also happens that the reported results are not exactly what one may believe it represents. Moreover, even if using these packages, it is always good to have in mind the meaning of statistics and how they are computed. Here the formulas for the most commonly used statistics with the general linear model (glm) are presented, all in matrix form, that can be easily implemented in Octave or Matlab.
I — Model
We consider two models, one univariate, another multivariate. The univariate is a particular case of the multivariate, but for univariate problems, it is simpler to use the smaller, particular case.
Univariate model
The univariate glm can be written as:
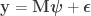
where 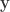 is the
is the  vector of observations,
vector of observations, 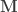 is the
is the  matrix of explanatory variables,
matrix of explanatory variables, 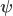 is the
is the  vector of regression coefficients, and
vector of regression coefficients, and  is the vector of residuals.
is the vector of residuals.
The null hypothesis can be stated as  , where
, where 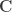 is a
is a  matrix that defines a contrast of regression coefficients, satisfying
matrix that defines a contrast of regression coefficients, satisfying 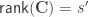 and
and  .
.
Multivariate model
The multivariate glm can be written as:

where 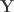 is the
is the  vector of observations, is the matrix of explanatory variables,
vector of observations, is the matrix of explanatory variables, 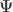 is the
is the 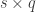 vector of regression coefficients, and is the vector of residuals.
vector of regression coefficients, and is the vector of residuals.
The null hypothesis can be stated as  , where is defined as above, and
, where is defined as above, and  is a
is a  matrix that defines a contrast of observed variables, satisfying
matrix that defines a contrast of observed variables, satisfying  and
and 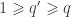 .
.
II — Estimation of parameters
In the model, the unknowns of interest are the values arranged in . These can be estimated as:

where the  represents a pseudo-inverse. The residuals can be computed as:
represents a pseudo-inverse. The residuals can be computed as:
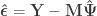
The above also applies to the univariate case ( is a particular case of , and of ).
III – Univariate statistics
Coefficient of determination, R2
The following is the fraction of the variance explained by the part of the model determined by the contrast. It applies to mean-centered data and design, i.e.,  and
and 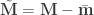 .
.

Note that the portion of the variance explained by nuisance variables (if any) remains in the denominator. To have these taken into account, consider the squared partial correlation coefficient, or Pillai’s trace with univariate data, both described further down.
Pearson’s correlation coefficient
When  , the multiple correlation coefficient can be computed from the
, the multiple correlation coefficient can be computed from the 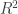 statistic as:
statistic as:
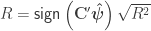
This value should not be confused, even in the presence of nuisance, with the partial correlation coefficient (see below).
Student’s t statistic
If , the Student’s  statistic can be computed as:
statistic can be computed as:
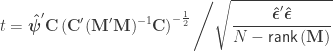
F statistic
The  statistic can be computed as:
statistic can be computed as:
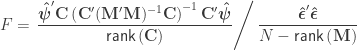
Aspin—Welch v
If homoscedastic variances cannot be assumed, and , this is equivalent to the Behrens—Fisher problem, and the Aspin—Welch’s statistic can be computed as:
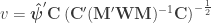
where  is a diagonal matrix that has elements:
is a diagonal matrix that has elements:
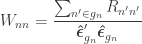
and where  are the
are the  diagonal elements of the residual forming matrix
diagonal elements of the residual forming matrix  , and
, and 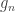 is the variance group to which the
is the variance group to which the  -th observation belongs.
-th observation belongs.
Generalised G statistic
If variances cannot be assumed to be the same across all observations, a generalisation of the statistic can be computed as:

where is defined as above, and the remaining denominator term,  , is given by:
, is given by:
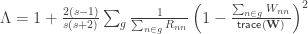
There is another post on the G-statistic (here).
Partial correlation coefficient
When , the partial correlation can be computed from the Student’s statistic as:

The square of the partial correlation corresponds to Pillai’s trace applied to an univariate model, and it can also be computed from the -statistic as:
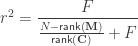
Likewise, if  is known, the formula can be solved for :
is known, the formula can be solved for :

or for :

The partial correlation can also be computed at once for all variables vs. all other variables as follows. Let ![\mathbf{A} = \left[\mathbf{y}\; \mathbf{M}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D+%3D+%5Cleft%5B%5Cmathbf%7By%7D%5C%3B+%5Cmathbf%7BM%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and
, and  be the inverse of the correlation matrix of the columns of
be the inverse of the correlation matrix of the columns of 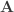 , and
, and 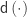 the diagonal operator, that returns a column vector with the diagonal entries of a square matrix. Then the matrix with the partial correlations is:
the diagonal operator, that returns a column vector with the diagonal entries of a square matrix. Then the matrix with the partial correlations is:

where 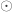 is the Hadamard product, and the power “
is the Hadamard product, and the power “ ” is taken elementwise (i.e., not matrix power).
” is taken elementwise (i.e., not matrix power).
IV – Multivariate statistics
For the multivariate statistics, define generically 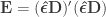 as the sums of the products of the residuals, and
as the sums of the products of the residuals, and 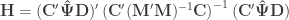 as the sums of products of the hypothesis. In fact, the original model can be modified as
as the sums of products of the hypothesis. In fact, the original model can be modified as  , where
, where 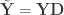 ,
, 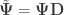 and
and  .
.
If  , this is an univariate model, otherwise it remains multivariate, although can be omitted from the formulas. From now on this simplification is adopted, so that
, this is an univariate model, otherwise it remains multivariate, although can be omitted from the formulas. From now on this simplification is adopted, so that 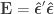 and
and  .
.
Hotelling T2
If , the Hotelling’s 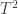 statistic can be computed as:
statistic can be computed as:

where 
Multivariate alternatives to the F statistic
Classical manova/mancova statistics can be based in the ratio between the sums of products of the hypothesis and the sums of products of the residuals, or the ratio between the sums of products of the hypothesis and the total sums of products. In other words, define:

Let  be the eigenvalues of , and
be the eigenvalues of , and 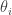 the eigenvalues of
the eigenvalues of 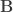 . Then:
. Then:
- Wilks’
 .
.
- Lawley–Hotelling’s trace:
 .
.
- Pillai’s trace:
 .
.
- Roy’s largest root (ii):
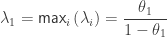 (analogous to ).
(analogous to ).
- Roy’s largest root (iii):
 (analogous to ).
(analogous to ).
When , or when is univariate, or both, Lawley–Hotelling’s trace is equal to Roy’s (ii) largest root, Pillai’s trace is equal to Roy’s (iii) largest root, and Wilks’ added to Pillai’s trace equals to unity. The value  is the
is the  -th canonical correlation.
-th canonical correlation.
References

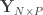
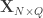
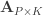
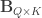
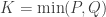
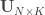


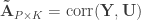

:
: