

Extreme values are useful to quantify the risk of catastrophic floods, and much more.
This is a brief set of notes with an introduction to extreme value theory. For reviews, see Leadbetter et al (1983) and David and Huser (2015) [references at the end]. Also of some (historical) interest might be the classical book by Gumbel (1958). Let 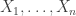
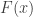
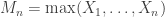
If

The distribution function
But before that, let’s make a small variable change. Working with 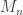

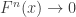
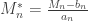


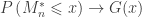
then 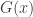
- Type I (Gumbel law):
, for
indicating that the distribution of
- Type II (Fréchet law):
indicating that the distribution of
- Type III (Weibull law):
indicating that the distribution of
Note that in the above formulation, the Weibull is reversed so that the distribution has an upper bound, as opposed to a lower one as in the Weibull distribution. Also, the parameterisation is slightly different than the one usually adopted for the Weibull distribution.
These three families have parameters 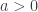



These three limiting cases are collectively termed extreme value distributions. Types II and III were identified by Fréchet (1927), whereas type I was found by Fisher and Tippett (1928). In his work, Fréchet used 
Generalised extreme value distribution
As shown above, the rescaled maxima converge in distribution to one of three families. However, all are cases of a single family that can be represented as:
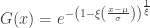
defined on the set 


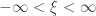
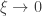
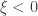


Generalised Pareto distribution
For 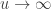

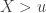
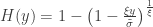
defined for 
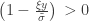
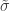
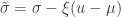
The above is sometimes called the Picklands-Baikema-de Haan theorem or the Second Theorem of Extreme Values, and it defines another family of distributions, known as generalised Pareto distribution (GPD). It generalises an exponential distribution with parameter 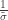
![\left[0, \tilde{\sigma}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B0%2C+%5Ctilde%7B%5Csigma%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
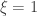

Parameter estimation
By restricting the attention to the most common case of 
For a set of extreme observations, let 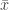
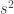


The accuracy of these estimates can be tested with, e.g., the Anderson-Darling goodness-of-fit test (Anderson and Darling, 1952; Choulakian and Stephens, 2001), based on the fact that, if the modelling is accurate, the p-values for the distribution should be uniformly distributed.
Availability
Statistics of extremes are used in PALM as a way to accelerate permutation tests. More details to follow soon.
References
- Anderson TW, Darling DA. Asymptotic theory of certain goodness of fit criteria based on stochastic processes. Ann Math Stat. 1952;23(2):193-212.
- Choulakian V, Stephens MA. Goodness-of-Fit Tests for the Generalized Pareto Distribution. Technometrics. 2001;43(4):478-84.
- Davison AC, Huser R. Statistics of Extremes. Annu Rev Stat Its Appl. 2015;2(1):203-35.
- Fisher RA, Tippett LHC. Limiting forms of the frequency distribution of the largest and smallest member of a sample. Proc Camb Philol Soc. 1928;24:180-90.
- Fréchet, M. Sur la loi de probabilité de l’écart maximum. Ann Soc Polon Math. 1927;6:93. [link currently not accessible due to copyright issues]
- Gnedenko B. Sur La Distribution Limite Du Terme Maximum D’Une Serie Aleatoire. Ann Math. 1943;44(3):423-53.
- Gumbel E. Statistics of Extremes. Echo Point Books & Media, 1958.
- Hosking JRM, Wallis JR. Parameter and quantile estimation for the generalized Pareto distribution. Technometrics. 1987;29:339-49.
- Knijnenburg TA, Wessels LFA, Reinders MJT, Shmulevich I. Fewer permutations, more accurate P-values. Bioinformatics. 2009 Jun 15;25(12):i161-8.
- Leadbetter MR, Lindgren G, Rootzén H. Extremes and related properties of
random sequences and processes. Springer-Verlag, New York, 1983. - Oliveira JT (ed). Proceedings of the NATO Advanced Study Institute on Statistical Extremes and Applications. D. Heidel, Dordrecht, Holland, 1984.
- Picklands III J. Statistical inference using extreme order statistics. Ann Stat. 1975;3(1):119-31.
- Tippett LHC. On the extreme individuals and the range of samples taken from a normal population. Biometrika. 1925;17(3):364-87.
- von Mises R. La distribution de la plus grande de n valeurs. Rev Mathématique l’Union Interbalkanique. 1936;1:141-60.
The figure at the top (flood) is in public domain.

I really enjoyed reading and remembering my college years! #kudos
Thanks Pedro Paulo!