
It’s so often that we find ourselves in the need to quickly compute a statistic for a certain dataset, but finding the formulas is not always direct. Using a statistical software is helpful, but it often also happens that the reported results are not exactly what one may believe it represents. Moreover, even if using these packages, it is always good to have in mind the meaning of statistics and how they are computed. Here the formulas for the most commonly used statistics with the general linear model (glm) are presented, all in matrix form, that can be easily implemented in Octave or Matlab.
I — Model
We consider two models, one univariate, another multivariate. The univariate is a particular case of the multivariate, but for univariate problems, it is simpler to use the smaller, particular case.
Univariate model
The univariate glm can be written as:
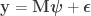
where 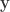

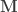

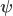


The null hypothesis can be stated as 
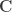

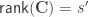

Multivariate model
The multivariate glm can be written as:

where 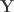

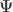
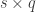
The null hypothesis can be stated as 



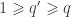
II — Estimation of parameters
In the model, the unknowns of interest are the values arranged in

where the 
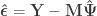
The above also applies to the univariate case (
III – Univariate statistics
Coefficient of determination, R2
The following is the fraction of the variance explained by the part of the model determined by the contrast. It applies to mean-centered data and design, i.e., 
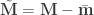

Note that the portion of the variance explained by nuisance variables (if any) remains in the denominator. To have these taken into account, consider the squared partial correlation coefficient, or Pillai’s trace with univariate data, both described further down.
Pearson’s correlation coefficient
When 
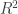
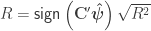
This value should not be confused, even in the presence of nuisance, with the partial correlation coefficient (see below).
Student’s t statistic
If 
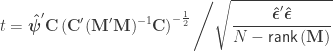
F statistic
The 
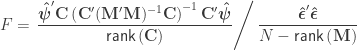
Aspin—Welch v
If homoscedastic variances cannot be assumed, and
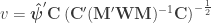
where 
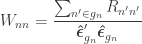
and where 


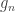

Generalised G statistic
If variances cannot be assumed to be the same across all observations, a generalisation of the

where 
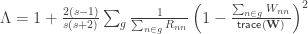
There is another post on the G-statistic (here).
Partial correlation coefficient
When

The square of the partial correlation corresponds to Pillai’s trace applied to an univariate model, and it can also be computed from the
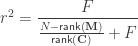
Likewise, if 

or for

The partial correlation can also be computed at once for all variables vs. all other variables as follows. Let ![\mathbf{A} = \left[\mathbf{y}\; \mathbf{M}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D+%3D+%5Cleft%5B%5Cmathbf%7By%7D%5C%3B+%5Cmathbf%7BM%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)

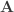

where 

IV – Multivariate statistics
For the multivariate statistics, define generically 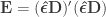
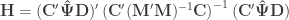

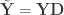
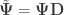

If 
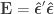

Hotelling T2
If 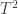

where

Multivariate alternatives to the F statistic
Classical manova/mancova statistics can be based in the ratio between the sums of products of the hypothesis and the sums of products of the residuals, or the ratio between the sums of products of the hypothesis and the total sums of products. In other words, define:

Let 
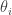
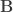
- Wilks’
.
- Lawley–Hotelling’s trace:
.
- Pillai’s trace:
.
- Roy’s largest root (ii):
(analogous to
- Roy’s largest root (iii):
(analogous to
When 

References
- Wilks S. Certain Generalizations in the Analysis of Variance. Biometrika. 1932;24(3):471-494.
- Lawley D. A Generalization of Fisher’s z Test. Biometrika. 1938;30(1):180-187.
- Hotelling H. A generalized T test and measure of multivariate dispersion. In: Neyman J, ed. Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press; 1951:23-41.
- Roy SN. On a Heuristic Method of Test Construction and its use in Multivariate Analysis. Ann Math Stat. 1953;24(2):220-238.
- Pillai KCS. Some New Test Criteria in Multivariate Analysis. Ann Math Stat. 1955;26(1):117-121.
- Winkler AM, Ridgway GR, Webster MA, Smith SM, Nichols TE. Permutation Inference for the general linear model. Neuroimage. 2014 May 15;92:381-97.
