Estimating the empirical cumulative distribution function (empirical cdf) from a set of observed values requires computing, for each value, how many of the other values are smaller or equal to it. In other words, let 

where 





For continuous distributions, a p-value for a given 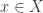



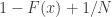
In the absence of repeated values (ties), the cdf can be obtained computationally by sorting the observed data in ascending order, i.e., 

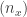
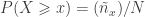

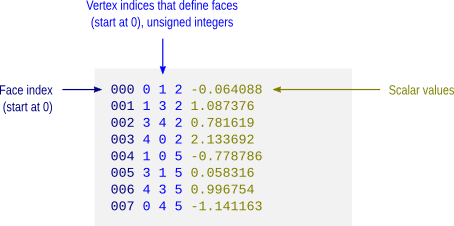
Example 1: Consider the following sequence of 10 observed values, already sorted in ascending order:
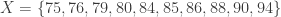
The corresponding ranks are simply 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. Consequently, the cdf is:

The p-values are computed by using the ranks in descending order, i.e., 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, which yields:
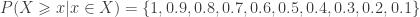
The problem with ties
Simple sorting, as above, is effective when there are no repeated values in the data. However, in the presence of ties, simple sorting that produces ordinal rankings yield incorrect results.
Example 2: Consider the following sequence of 10 observed values, in which ties are present:

If the same computational strategy discussed above were used, the we would conclude that the p-value for 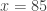
The competition ranking
The competition ranking assigns the same rank to values that are identical. The standard competition ranking for the previous sequence is, in ascending order, 1, 1, 3, 4, 4, 4, 7, 8, 8, 8. In descending order, the ranks are 9, 9, 8, 5, 5, 5, 4, 1, 1, 1. Note that in this ranking, the ties receive the “best” possible rank. A slightly different approach consists in assigning the “worst” possible rank to the ties. This modified competition ranking applied the previous sequence gives, in ascending order, the ranks 2, 2, 3, 5, 5, 5, 7, 10, 10, 10, whereas in descending order, the ranks are 10, 10, 8, 7, 7, 7, 4, 3, 3, 3.
Competition ranking solves the problem with ties for both the empirical cdf and for the calculation of the p-values. In both cases, it is the modified version of the ranking that needs to be used, i.e., the ranking that assigns the worst rank to identical values. Still using the same sequence as example, the cdf is given by:
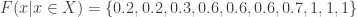
and the p-values are given by:
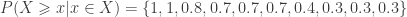
Note that, as in the case with no ties, the p-values cannot be computed simply as 
Uses
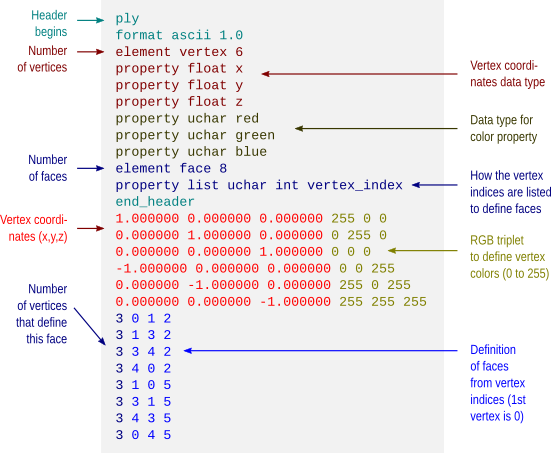
The cdf of a set of observed data is useful in many types of non-parametric inference, particularly those that use bootstrap, jack-knife, Monte Carlo, or permutation tests. Ties can be quite common when working with discrete data and discrete explanatory variables using any of these methods.
Competition ranking in MATLAB and Octave
A function that computes the competition ranks for Octave and/or MATLAB is available to download here: csort.m.
Once installed, type help csort to obtain usage information.
References
Papoulis A. Probability, Random Variables and Stochastic Processes. McGraw-Hill, New York, 3rd ed, 1991.



 , where
, where  is the number of images averaged.
is the number of images averaged.

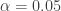 to obtain a 95% confidence interval. For each of the methods, the interval is shown graphically for
to obtain a 95% confidence interval. For each of the methods, the interval is shown graphically for  and
and  .
.

 ,
,  is the
is the  and
and  .
.


 ,
,  ,
, 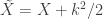 , and the remaining are as above. This is probably the most appropriate for the majority of situations.
, and the remaining are as above. This is probably the most appropriate for the majority of situations.


 , and the remaining are as above.
, and the remaining are as above.
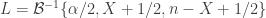

 is the inverse
is the inverse 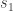 and
and 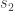 .
.
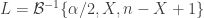


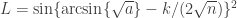
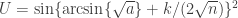
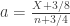 replaces what otherwise would be
replaces what otherwise would be  (
(
 . It is defined as:
. It is defined as:

 ,
,  , and
, and  .
.
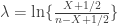 and
and 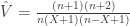 . The values for
. The values for  and
and  are as above.
are as above.








 based on their respective p-values,
based on their respective p-values,  . Consider that a fraction
. Consider that a fraction  of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,
of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,  and denote
and denote  the hypothesis corresponding to
the hypothesis corresponding to  . Let
. Let  be the largest
be the largest  for which
for which  . Then reject all
. Then reject all 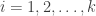 . The constant
. The constant  is not in the original publication, and appeared in
is not in the original publication, and appeared in  or
or  . The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by
. The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by  . This formulation, however, has problems, as discussed next.
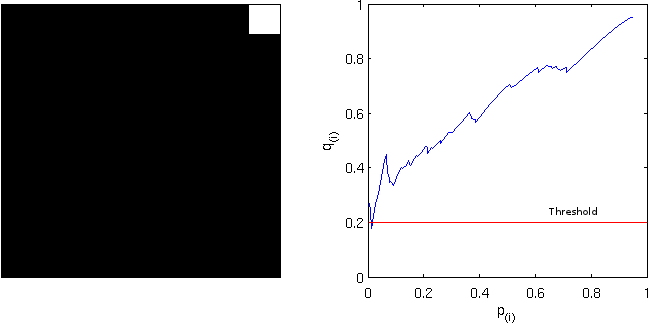
. This formulation, however, has problems, as discussed next. is not a monotonic function of
is not a monotonic function of  be the FDR-adjusted value for
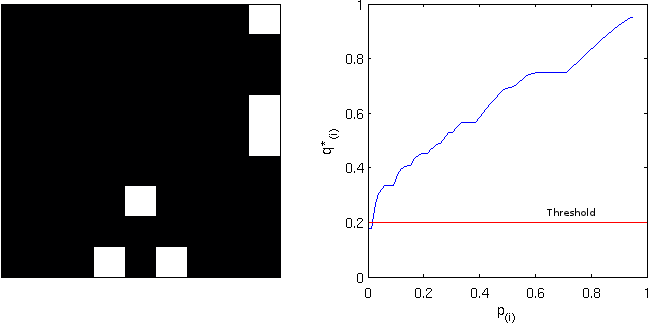
be the FDR-adjusted value for  , where
, where 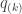 is the FDR-corrected as defined above. That’s just it!
is the FDR-corrected as defined above. That’s just it!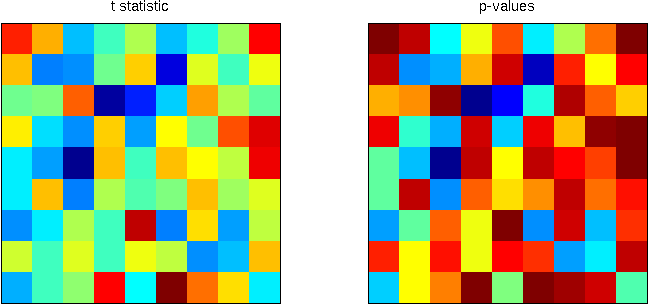
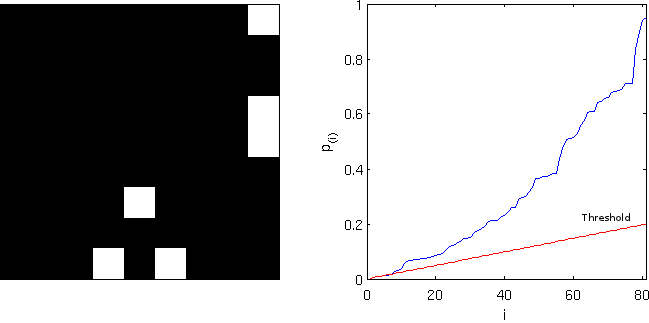
 , and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.
, and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.