
Consider a set of 

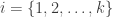

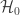
There are a number of ways to combine these independent, partial tests. The Fisher method is one of these, and is perhaps the most famous and most widely used. The test was presented in Fisher’s now classical book, Statistical Methods for Research Workers, and was described rather succinctly:
When a number of quite independent tests of significance have been made, it sometimes happens that although few or none can be claimed individually as significant, yet the aggregate gives an impression that the probabilities are on the whole lower than would often have been obtained by chance. It is sometimes desired, taking account only of these probabilities, and not of the detailed composition of the data from which they are derived, which may be of very different kinds, to obtain a single test of the significance of the aggregate, based on the product of the probabilities individually observed.
The circumstance that the sum of a number of values ofis itself distributed in the
, the natural logarithm of the probability is equal to
. If therefore we take the natural logarithm of a probability, change its sign and double it, we have the equivalent value of
The test is based on the fact that the probability of rejecting the global null hypothesis is related to intersection of the probabilities of each individual test, 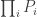
The logarithm of uniform is exponential
The cumulative distribution function (cdf) of an exponential distribution is:
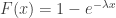
where 

If 
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
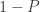
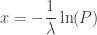
where 

An exponential with rate 1/2 is chi-squared
The cdf of a chi-squared distribution with 

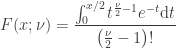
If 

In other words, a 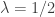
The sum of chi-squared is also chi-squared
The moment-generating function (mgf) of a sum of independent variables is the product of the mgfs of the respective variables. The mgf of a
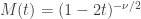
The mgf of the sum of 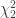
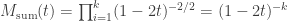
which also defines a 
Assembling the pieces
With these facts in mind, how to transform the product 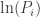

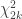
The statistic for the Fisher method is, therefore, computed as:

with 
Reference
The details above are not in the book, presumably omitted by Fisher as the knowledge of these derivation details would be of little practical use. Nonetheless, the reference for the book is:
- Fisher, R. A., 1932. Statistical Methods for Research Workers, 4th Edition. Oliver and Boyd, Edinburgh.
See also
The Fisher’s method to combine p-values is one of the most powerful combining functions that can be used for Non-Parametric Combination.
 trials, with
trials, with 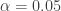 to obtain a 95% confidence interval. For each of the methods, the interval is shown graphically for
to obtain a 95% confidence interval. For each of the methods, the interval is shown graphically for  and
and 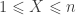 .
.

 ,
,  is the
is the  and
and 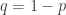 .
.


 ,
,  ,
, 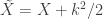 , and the remaining are as above. This is probably the most appropriate for the majority of situations.
, and the remaining are as above. This is probably the most appropriate for the majority of situations.


 , and the remaining are as above.
, and the remaining are as above.
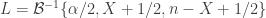

 is the inverse
is the inverse  , and with shape parameters
, and with shape parameters 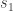 and
and 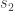 .
.
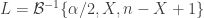


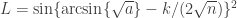
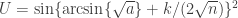
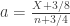 replaces what otherwise would be
replaces what otherwise would be  (
(
 . It is defined as:
. It is defined as:

 ,
,  , and
, and  .
.
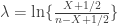 and
and 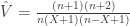 . The values for
. The values for  and
and 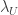 are as above.
are as above.
 hypotheses,
hypotheses,  based on their respective p-values,
based on their respective p-values,  . Consider that a fraction
. Consider that a fraction  of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,
of discoveries are allowed (tolerated) to be false. Sort the p-values in ascending order,  and denote
and denote  the hypothesis corresponding to
the hypothesis corresponding to  . Let
. Let  for which
for which  . Then reject all
. Then reject all 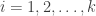 . The constant
. The constant  is not in the original publication, and appeared in
is not in the original publication, and appeared in 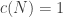 or
or  . The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by
. The second is valid in any situation, whereas the first is valid for most situations, particularly where there are no negative correlations among tests. The B&H procedure has found many applications across different fields, including neuroimaging, as introduced by  . This formulation, however, has problems, as discussed next.
. This formulation, however, has problems, as discussed next. is not a monotonic function of
is not a monotonic function of  be the FDR-adjusted value for
be the FDR-adjusted value for  , where
, where 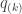 is the FDR-corrected as defined above. That’s just it!
is the FDR-corrected as defined above. That’s just it!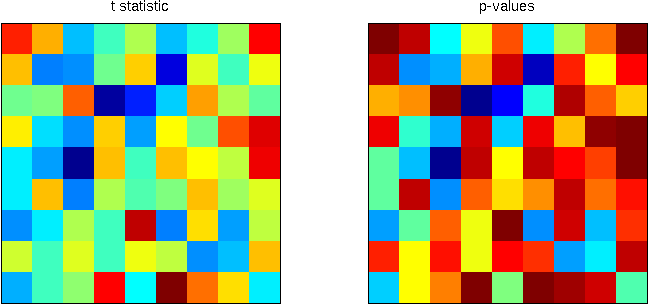
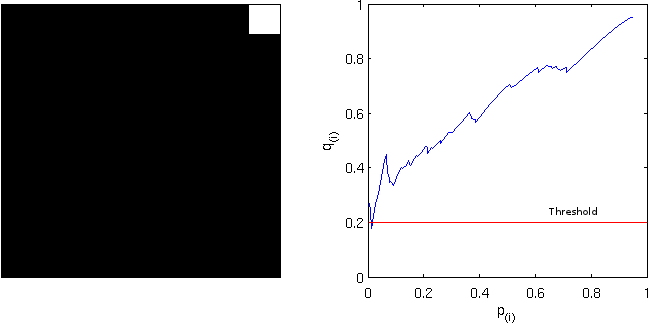
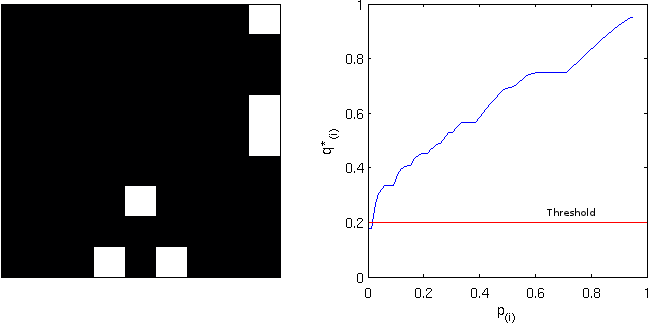
 , and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.
, and applying this threshold to the image rejects the null hypothesis in 6 pixels. On the right panel, the red line corresponds to the threshold. All p-values (in blue) below this line are declared significant.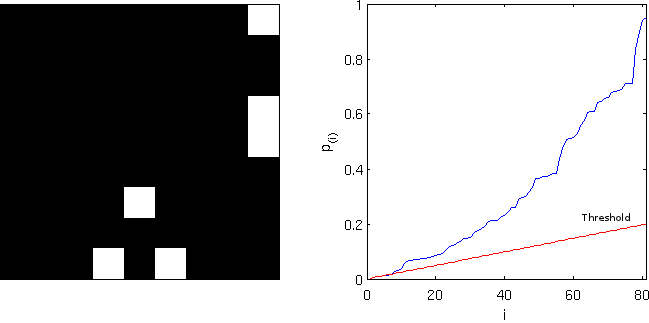
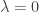 . Plotting the transformation as a function of the original data
. Plotting the transformation as a function of the original data  and the parameter
and the parameter 
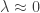 , the original data tend to be log-normally distributed, whereas if
, the original data tend to be log-normally distributed, whereas if  , the data can be considered approximately more normally distributed.
, the data can be considered approximately more normally distributed.
 is the transformed value for observation
is the transformed value for observation  is the
is the  is the ordinary rank of the
is the ordinary rank of the 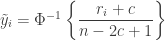
 is a constant and the remaining variables are as above. The value of
is a constant and the remaining variables are as above. The value of  , Tukey (1962) suggests
, Tukey (1962) suggests  , Bliss (1967) suggests
, Bliss (1967) suggests 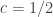 and, as just decribed, Van der Waerden suggests
and, as just decribed, Van der Waerden suggests 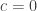 .
.")
")
")
")
")
")
 statistic had a poor and erratic behaviour for sample sizes smaller than 200, particularly at the low significance levels, which are generally the ones of greatest interest. For this test, Monte Carlo simulations to derive the critical values are highly recommended.
statistic had a poor and erratic behaviour for sample sizes smaller than 200, particularly at the low significance levels, which are generally the ones of greatest interest. For this test, Monte Carlo simulations to derive the critical values are highly recommended.")
")
")
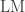 statistic is not valid for small p-values for any of the sample sizes tested, although for sample sizes >1500 the behaviour was reasonably stable. Monte Carlo simulations also more appropriate for this test.
statistic is not valid for small p-values for any of the sample sizes tested, although for sample sizes >1500 the behaviour was reasonably stable. Monte Carlo simulations also more appropriate for this test.")
")
")
 statistic seems adequate for sample sizes larger than 15 and smaller than 4000, being slightly anticonservative for most p-values at sample sizes smaller than 20. It has aberrant behaviour at p-values close to 1, which are generally of no interest anyway.
statistic seems adequate for sample sizes larger than 15 and smaller than 4000, being slightly anticonservative for most p-values at sample sizes smaller than 20. It has aberrant behaviour at p-values close to 1, which are generally of no interest anyway.")
")
")
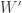 statistic, the asymptotic behaviour is similar to the observed for the Shapiro-Wilk test, except that it remains valid for sample sizes larger than 4000.
statistic, the asymptotic behaviour is similar to the observed for the Shapiro-Wilk test, except that it remains valid for sample sizes larger than 4000.")
")
")
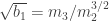 , where
, where 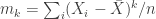 is the k-th moment,
is the k-th moment,  is the sample mean, and
is the sample mean, and 
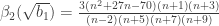

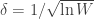


 is the test statistic and it is approximately normally distributed under the null hypothesis that the population data follows a normal distribution.
is the test statistic and it is approximately normally distributed under the null hypothesis that the population data follows a normal distribution.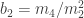 , where
, where 



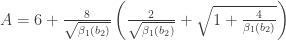 , where
, where  and
and  represent respectively the expected value and the variance.
represent respectively the expected value and the variance.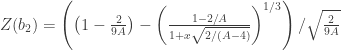
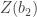 is the test statistic and is considered approximately normally distributed under the null hypothesis that the population data follows a normal distribution.
is the test statistic and is considered approximately normally distributed under the null hypothesis that the population data follows a normal distribution. . In other words, simply square the statistics from the skewness and kurtosis tests and sum them together. The distribution of the
. In other words, simply square the statistics from the skewness and kurtosis tests and sum them together. The distribution of the  . The
. The  is asymptotically distributed as a
is asymptotically distributed as a  , where
, where 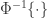 represents the inverse normal cdf.
represents the inverse normal cdf. . These weights are the same used in the Shapiro-Francia test (see below).
. These weights are the same used in the Shapiro-Francia test (see below).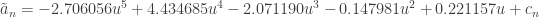 , where
, where  . If
. If  , compute also
, compute also  .
. if
if 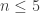 or
or  otherwise.
otherwise. for
for 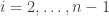 if
if  if
if  .
.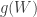 to a normal distribution with mean
to a normal distribution with mean  and standard deviation
and standard deviation  (
( , where
, where 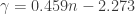 . For sample sizes equal to or larger than 12,
. For sample sizes equal to or larger than 12,  .
. , the parameters of the statistic transformed (normalized) by
, the parameters of the statistic transformed (normalized) by 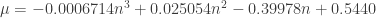 and
and 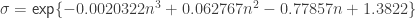 . For
. For  ,
,  and
and 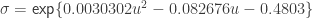 , where
, where  .
. statistic can then be produced trivially by
statistic can then be produced trivially by  , and the p-values can be obtained from the normal cdf.
, and the p-values can be obtained from the normal cdf. .
. to a normal distribution with mean
to a normal distribution with mean  are given by
are given by  , where
, where 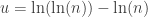 and
and  , where
, where  . These approximations are valid for samples between 5 and 5000 at least.
. These approximations are valid for samples between 5 and 5000 at least.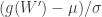 , and the p-values can be obtained from the normal cdf.
, and the p-values can be obtained from the normal cdf.