
SOLAR software can, at the discretion of the user, apply a rank-based inverse-normal transformation to the data using the command inormal. This transformation is the one suggested by Van der Waerden (1952) and is given by:

where 




This transformation is a particular case of the family of transformations discussed in the paper by Beasley et al. (2009). The family can be represented as:
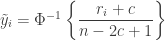
where 


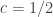
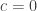
Interesting enough, the Q-Q plots produced by Octave use the Bliss (1967) transformation.
An Octave/matlab function to perform these transformations in arbitrary data is here: inormal.m (note that this function does not require or use SOLAR).
References
- Van der Waerden BL. Order tests for the two-sample problem and their power. Proc Koninklijke Nederlandse Akademie van Wetenschappen. Ser A. 1952; 55:453–458.
- Blom G. Statistical estimates and transformed beta-variables. Wiley, New York, 1958 (page 71).
- Tukey JW. The future of data analysis. Ann Math Stat. 1962; 33:1–67.
- Bliss CI. Statistics in biology. McGraw-Hill, New York, 1967 (pages 117–120).
- Beasley TM, Erickson S, Allison DB. Rank-based inverse normal transformations are increasingly used, but are they merited? Behav Genet. 2009; 39(5):580-95.
Version history
- 23.Jul.2011: First public release.
- 19.Jun.2014: Added ability to deal with ties, as well as NaNs in the data.

Useful! Here is a function to do the same thing in Python.
from scipy.stats import rankdata, norm
def rank_based_inv_norm(x, c=0):
“””
Perform the rank-based inverse normal transformation on data x.
Reference: Beasley TM, Erickson S, Allison DB. Rank-based inverse normal
transformations are increasingly used, but are they merited? Behav Genet.
2009; 39(5):580-95.
:param x: input array-like
:param c: constant parameter
:return: y
“””
return norm.ppf((rankdata(x) + c) / (x.size – 2*c + 1))
Hey Sam — good to have this in other languages. You may need to add the extra lines to treat ties, otherwise the results aren’t accurate for all cases. Also note that the default is c=3/8, whereas you’re using c=0 (both are fine, just different).
Cheers,
Anderson
I chose c=0 because most of the time we will probably want to replicate the SOLAR output (in the IoL lab anyway).
scipy.rankdata has a number of optional methods for handling ties, the default is ‘average’, which I just assumed was the one SOLAR used, but couldn’t find a reference. For continuous traits with high precision the probability of tied ranks is quite low, so I think this function will give us the same output as SOLAR most of the time, but need to check this.