
Before the fast computers era, it was difficult to test how valid certain statistical methods were. Even in the 1970’s and 1980’s, when computers were already available at Universities and even at home, certain matrix operations were limited by hardware constraints. We are now at a much more comfortable position to analyse how these methods perform. One area where (nowadays) simple computer runs can be illuminating is with respect to normality tests. Tests to evaluate normality or a specific distribution, frequentist approaches can be broadly divided into two categories:
- Tests based on comparison (“best fit”) with a given distribution, often specified in terms of its cumulative distribution funtion (cdf). Examples are the Kolmogorov-Smirnov test, the Lilliefors test, the Anderson-Darling test, the Cramér-von Mises criterion, as well as the Shapiro-Wilk and Shapiro-Francia tests.
- Tests based on descriptive statistics of the sample. Examples are the skewness test, the kurtosis test, the D’Agostino-Pearson omnibus test, the Jarque-Bera test.
In this article I’ll briefly review six well-known normality tests: (1) the test based on skewness, (2) the test based on kurtosis, (3) the D’Agostino-Pearson omnibus test, (4) the Shapiro-Wilk test, (5) the Shapiro-Francia test, and (6) the Jarque-Bera test. In a subsequent article, I’ll analyse the analytical p-value approximations for these tests, and in a third article, I’ll provide Monte Carlo critical values for each of them.
Skewness test
The skewness of the sample data can be converted to an useful score to evaluate normality with the following transformation (D’Agostino, 1970):
- Compute the sample skewness
, where
is the k-th moment,
is the sample mean, and
is the sample size.
- Compute:
- Compute:

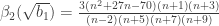

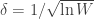


The 
Kurtosis test
Like the test based on skewness, the test based on kurtosis needs that the sample kurtosis is calculated, then transformed, and finally converted to a p-value. The steps are (Anscombe & Glynn, 1983):
- Compute the sample kurtosis
, where
- Compute:
, where
and
represent respectively the expected value and the variance.
- Compute:




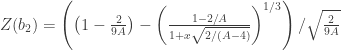
The 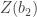
D’Agostino-Pearson omnibus test
The skewness and kurtosis tests can be combined to produce a single, global, “omnibus” statistic. This global test has been proposed by D’Agostino and Pearson (1973) and its statistic is simply 


A matlab/Octave implementation of the D’Agostino-Pearson test is available here: daptest.m.
Jarque-Bera test
In a certain regard, this test, introduced by Jarque & Bera (1980) and later discussed in more detail in Jarque & Bera (1987), could also be called an “omnibus” test, that combines skewness and kurtosis into a single statistic. The test statistic is given by 

A matlab/Octave implementation of the Jarque-Bera test is available here: jbtest.m.
Shapiro-Wilk test
The Shapiro & Wilk (1965) test depends on the covariance matrix between the order statistics of the observations. Values for this covariance matrix have been laboriously tabulated for small samples (Sahan & Greenberg,1956) and algorithms have been developed (Davis & Stephens, 1978; Royston, 1982). In an effort to produce equivalents, yet computationally affordable results, it has been suggested to use approximations. The description here follow the approximation suggested by Royston (1992).
- Sort the data in ascending order.
- Compute the sample mean
- Compute the Blom scores (Blom, 1958) as
, where
is the rank order and
represents the inverse normal cdf.
- Compute a set of weights
. These weights are the same used in the Shapiro-Francia test (see below).
- Compute
, where
. If
, compute also
.
- Compute
if
or
otherwise.
- Compute the remaining
for
if
if
- Compute the test statistic
.
Once the test statistic 
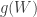



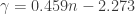

For 
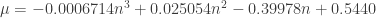
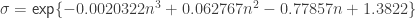


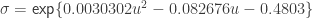

A 

A matlab/Octave implementation of the Shapiro-Wilk test is available here: swtest.m.
Shapiro-Francia test
The test was proposed by Shapiro & Francia (1972) as a simplification of the Shapiro-Wilk test. The simplification consisted in replacing the covariance matrix of the order statistics by the identity matrix. The test is generally considered asymptotically equivalent to the Shapiro-Wilk test for large and independent samples. To apply the test, the steps are (Royston, 1993):
- Sort the data in ascending order.
- Compute the sample mean
- Compute the Blom scores (Blom, 1958) as
- Compute a set of weights
- Compute the test statistic
.
Similarly as for the Shapiro-Wilk test, once the test statistic 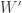



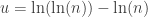


A 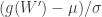
A matlab/Octave implementation of the Shapiro-Francia test is available here: sftest.m.
References
- Anscombe FJ, Glynn WJ. Distribution of the Kurtosis Statistic b 2 for Normal Samples. Biometrika. 1983; 70(1):227-34.
- Blom G. Statistical Estimates and Transformed Beta-Variables. New York, NY. John Wiley & Sons, 1958.
- DʼAgostino RB. Transformation to Normality of the Null Distribution of g1. Biometrika. 1970; 57(3):679-81.
- DʼAgostino RB, Belanger A, DʼAgostino Jr RB. A Suggestion for Using Powerful and Informative Tests of Normality. The American Statistician. 1990; 44(4):316-21.
- DʼAgostino R, Pearson ES. Tests for Departure from Normality. Empirical Results for the Distributions of b 2 and √b 1. Biometrika. 1973; 60(3):613-22.
- Davis C, Stephens M. Approximating the Covariance Matrix of Normal Order Statistics. Applied Statistics. 1978; 27(2):206-212.
- Jarque CM, Bera AK. A Test for Normality of Observations and Regression Residuals. International Statistical Review/Revue Internationale de Statistique. 1987; 55(2):163–172.
- Jarque CM, Bera AK. Efficient tests for normality, homoscedasticity and serial independence of regression residuals. Economics Letters. 1980; 6(3):255-259.
- Royston P. Approximating the Shapiro-Wilk W-test for non-normality. Statistics and Computing. 1992; 2(3):117-119.
- Royston P. A Toolkit for Testing for Non-Normality in Complete and Censored Samples. The Statistician. 1993; 42(1):37.
- Royston JP. Algorithm AS 177: Expected normal order statistics (exact and approximate). Journal of the Royal Statistical Society. Series C (Applied Statistics). 1982; 31(2):161–165.
- Sarhan AE, Greenberg BG. Estimation of location and scale parameters by order statistics from singly and doubly censored samples. The Annals of Mathematical Statistics. 1956; 27(2):427–451.
- Shapiro SS, Wilk MB. An analysis of variance test for normality (complete samples). Biometrika. 1965; 52(3-4):591-611.
- Shapiro SS, Francia R. An approximate analysis of variance test for normality. Journal of the American Statistical Association. 1972; 67(337):215–216.

Pingback: Normality tests II: Asymptotic approximations « Brainder.
Pingback: Singapore Government Securities Yields: A Multi-Factor Heath, Jarrow And Morton Model | OptionFN
Pingback: Carlin cap Lessons From The U.S. Treasury Market, 1962-2019 – Premier league
After computing the k2 How would I know if I am going to reject the null hypothesis or not in using D’Agostino-Pearson omnibus test?
Hi Nash,
The D’Agostino-Pearson K^2 statistic follows a Chi^2 distribution with 2 degrees of freedom, from which p-values can be computed.
Hope this helps!
All the best,
Anderson
Pingback: A 10 Factor Heath, Jarrow and Morton Stochastic Volatility Model for the U.S. Treasury Yield Curve, Using Daily Data from January 1, 1962 through December 31, 2020 - Kamakura Corporation
Pingback: A 10 Factor Heath, Jarrow, and Morton Stochastic Volatility Model for the U.S. Treasury Yield Curve, Using Daily Data from January 1, 1962 through June 30, 2021 - Kamakura Corporation
Pingback: A 7-Factor Heath, Jarrow, and Morton Stochastic Volatility Model for the Government of Canada Yield Curve, Using Daily Data from January 2, 2001 through August 31, 2021 - Kamakura Corporation
Pingback: An 11-Factor Heath, Jarrow, and Morton Stochastic Volatility Model for the Government of Russia Yield Curve, Using Daily Data from January 4, 2003 through August 31, 2021 - Kamakura Corporation
Pingback: A 15-Factor Heath, Jarrow, and Morton Stochastic Volatility Model for the German Bund Yield Curve, Using Daily Data from August 7, 1997 through September 30, 2021 - Kamakura Corporation
Pingback: A 10-Factor Heath, Jarrow, and Morton Stochastic Volatility Model for the U.S. Treasury Yield Curve, Using Daily Data from January 1, 1962 through September 30, 2021 - Kamakura Corporation