
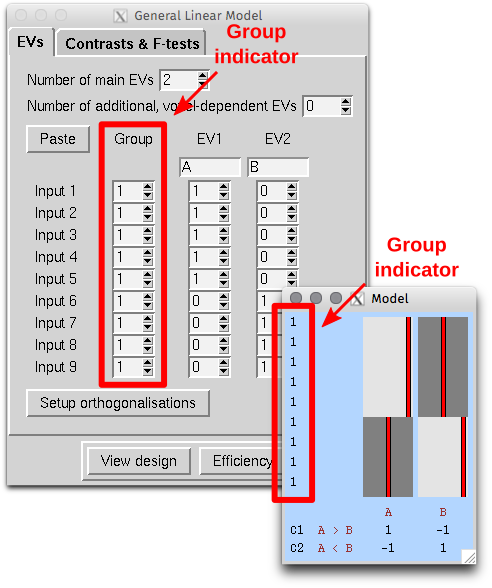
In FSL, when we create a design using the graphical interface in FEAT, or with the command Glm, we are given the opportunity to define, at the higher-level, the “Group” to which each observation belongs. When the design is saved, the information from this setting is stored in a text file named something as “design.grp”. This file, and thus the group setting, takes different roles depending whether the analysis is used in FEAT itself, in PALM, or in randomise.
What can be confusing sometimes is that, in all three cases, the “Group” indicator does not refer to experimental or observational group of any sort. Instead, it refers to variance groups (VG) in FEAT, to exchangeability blocks (EB) in randomise, and to either VG or EB in PALM, depending on whether the file is supplied with the options -vg or -eb.
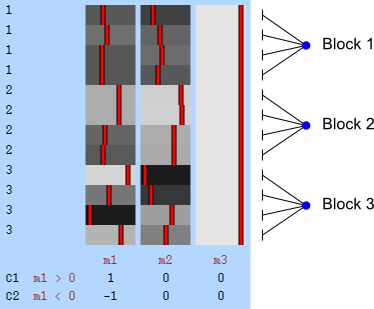
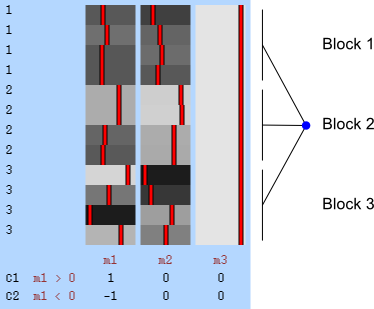
In FEAT, unless there is reason to suspect (or assume) that the variances for different observations are not equal, all subjects should belong to group “1”. If variance groups are defined, then these are taken into account when the variances are estimated. This is only possible if the design matrix is “separable”, that is, it must be such that, if the observations are sorted by group, the design can be constructed by direct sum (i.e., block-diagonal concatenation) of the design matrices for each group separately. A design is not separable if any explanatory variable (EV) present in the model crosses the group borders (see figure below). Contrasts, however, can encompass variables that are defined across multiple VGs.
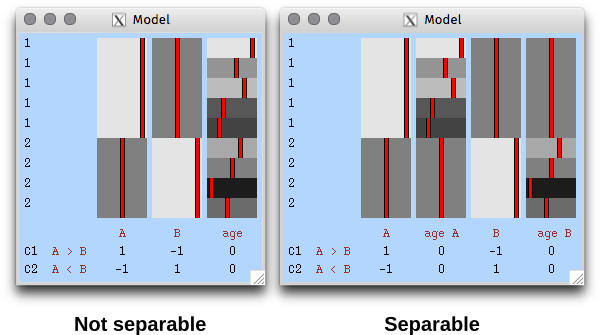
The variance groups not necessarily must match the experimental observational groups that may exist in the design (for example, in a comparison of patients and controls, the variance groups may be formed based on the sex of the subjects, or another discrete variable, as opposed to the diagnostic category). Moreover, the variance groups can be defined even if all variables in the model are continuous.
In randomise, the same “Group” setting can be supplied with the option -e design.grp, thus defining exchangeability blocks. Observations within a block can only be permuted with other observations within that same block. If the option --permuteBlocks is also supplied, then the EBs must be of the same size, and the blocks as a whole are instead then permuted. Randomise does not use the concept of variance group, and all observations are always members of the same single VG.
In PALM, using -eb design.grp has the same effect that -e design.grp has in randomise. Further using the option -whole is equivalent to using --permuteBlocks in randomise. It is also possible to use together -whole and -within, meaning that the blocks as a whole are shuffled, and further, observations within block are be shuffled. In PALM the file supplied with the option -eb can have multiple columns, indicating multi-level exchangeability blocks, which are useful in designs with more complex dependence between observations. Using -vg design.grp causes PALM to use the v– or G-statistic, which are replacements for the t– and F-statistics respectively for the cases of heterogeneous variances. Although VG and EB are not the same thing, and may not always match each other, the VGs can be defined from the EBs, as exchangeability implies that some observations must have same variance, otherwise permutations are not possible. The option -vg auto defines the variance groups from the EBs, even for quite complicated cases.
In both FEAT and PALM, defining VGs will only make a difference if such variance groups are not balanced, i.e., do not have the same number of observations, since heteroscedasticity (different variances) only matter in these cases. If the groups have the same size, all subjects can be allocated to a single VG (e.g., all “1”).
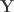 contains the experimental data,
contains the experimental data, 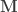 contains the regressors,
contains the regressors, 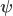 the regression coefficients, which are to be estimated, and
the regression coefficients, which are to be estimated, and  the residuals. For a linear null hypothesis
the residuals. For a linear null hypothesis  , where
, where 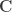 is a contrast. If
is a contrast. If  , the Student’s t statistic can be calculated as:
, the Student’s t statistic can be calculated as: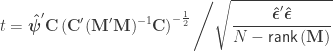
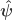 and
and 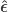 indicate that these are quantities estimated from the sample. If
indicate that these are quantities estimated from the sample. If 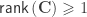 , the F statistic can be obtained as:
, the F statistic can be obtained as: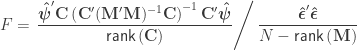
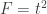 . For either of these statistics, we can assess their significance by repeating the same fit after permuting
. For either of these statistics, we can assess their significance by repeating the same fit after permuting 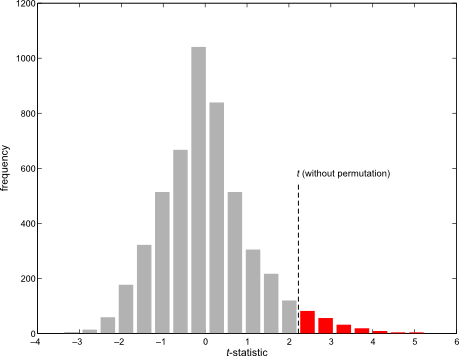
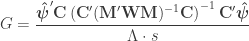
 is a diagonal matrix that has elements:
is a diagonal matrix that has elements: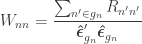
 are the
are the  diagonal elements of the residual forming matrix, and
diagonal elements of the residual forming matrix, and 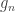 is the variance group to which the
is the variance group to which the  -th observation belongs. The remaining denominator term,
-th observation belongs. The remaining denominator term,  , is given by
, is given by 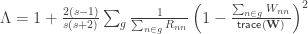
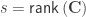 . The matrix
. The matrix 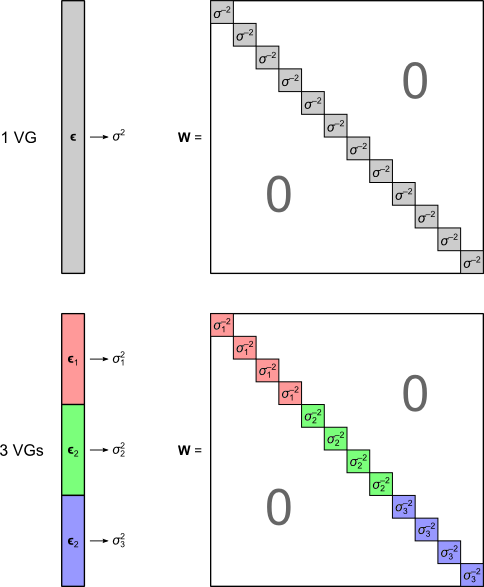
 , the t-equivalent to the G-statistic is
, the t-equivalent to the G-statistic is 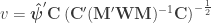 , which is the well known Aspin-Welch
, which is the well known Aspin-Welch  -statistic for the Behrens-Fisher problem. The relationship between
-statistic for the Behrens-Fisher problem. The relationship between 

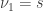 and
and  .
.