

When we run a permutation test, what we do is to first compute the statistic for the unpermuted model, then shuffle the data randomly, compute a new statistic and, if it is larger than the statistic for the unpermuted model, increment a counter. We then repeat the random shuffling, and keep incrementing the counter until we think we are done with them. We then divide the counter by the number of permutations and the result is the p-value what we wanted to find.
This procedure can be stated as:

where 

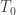


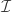


The problem
This strategy, however, has a problem. If the true p-value, 

Biasing to solve the problem
The solution is to make two modifications to the formulation above: start counting the 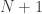

This formulation, which pools the unpermuted model together with the permuted realisations, is biased: for 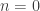

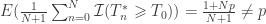
Quantifying the bias
The bias is smaller for a large number of permutations, and converges to zero as 

The bias is larger for smaller number of permutations and for smaller true p-values.
Controversy
The solution has been proposed by some authors, such as Edgington (1995), and strongly advocated by, e.g., Phipson and Smyth (2010). While the biased solution is definitely the most adequate for practical scientific problems, it can be considered as of little actual statistical meaning. Pesarin and Salmaso (2010) explain that the distribution of
References
- Edgington ES. Randomization Tests. 3rd ed. Dekker, 1995.
- Pesarin F and Salmaso L. Permutation Tests for Complex Data. Wiley, 2010.
- Phipson B and Smith GK. Permutation P-values should never be zero: calculating exact P-values when permutations are randomly drawn. Stat Appl Genet Mol Biol. 2010;9:Article39.
