

When we run a permutation test, what we do is to first compute the statistic for the unpermuted model, then shuffle the data randomly, compute a new statistic and, if it is larger than the statistic for the unpermuted model, increment a counter. We then repeat the random shuffling, and keep incrementing the counter until we think we are done with them. We then divide the counter by the number of permutations and the result is the p-value what we wanted to find.
This procedure can be stated as:

where 

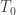


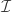


The problem
This strategy, however, has a problem. If the true p-value, 

Biasing to solve the problem
The solution is to make two modifications to the formulation above: start counting the 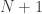

This formulation, which pools the unpermuted model together with the permuted realisations, is biased: for 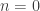

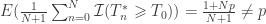
Quantifying the bias
The bias is smaller for a large number of permutations, and converges to zero as 

The bias is larger for smaller number of permutations and for smaller true p-values.
Controversy
The solution has been proposed by some authors, such as Edgington (1995), and strongly advocated by, e.g., Phipson and Smyth (2010). While the biased solution is definitely the most adequate for practical scientific problems, it can be considered as of little actual statistical meaning. Pesarin and Salmaso (2010) explain that the distribution of
References
- Edgington ES. Randomization Tests. 3rd ed. Dekker, 1995.
- Pesarin F and Salmaso L. Permutation Tests for Complex Data. Wiley, 2010.
- Phipson B and Smith GK. Permutation P-values should never be zero: calculating exact P-values when permutations are randomly drawn. Stat Appl Genet Mol Biol. 2010;9:Article39.

nothing new here. the original data IS one of the possible permutations of the pooled data – so one should have been using N+1 [in the above notation] all along.
Hi,
Thanks for the comment. There’s absolutely nothing new here: the P-values are indeed biased, as they should be. If, for whatever reason, one wants unbiased, N should be used, as opposed to N+1. The empirical distribution is merely an approximation of the true, underlying continuous distribution, that could be recovered asymptotically. As N cannot grow to infinity, we take the conservative approach, that is the one of practical use.
Even considering the possibility of using N in the denominator would create the paradoxical situation of increasing the likelihood of obtaining the most extreme possible significant result (that is, p=0) as the number of permutations decreases, something clearly unacceptable. Hence the title: it should be biased.
Note, however, that even though the original data is one the possible rearrangements, the decision of forcing its incusion in the permutation distribution is arbitrary — a mere choice done by the researcher whenever fewer than the largest possible number of permutations is performed (in practice, the “choice” is not really a choice, and the inclusion of the unpermuted data is compulsory as the article tries to highlight). If all the permutations are performed, the smallest possible p-value is simply 1/N, following the definition.
Anderson